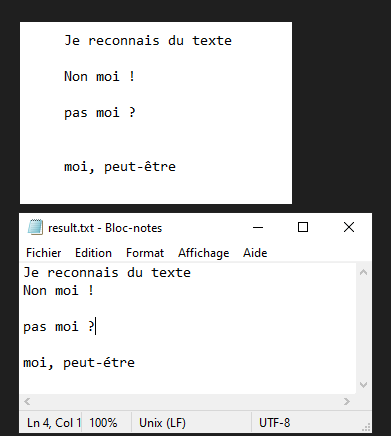
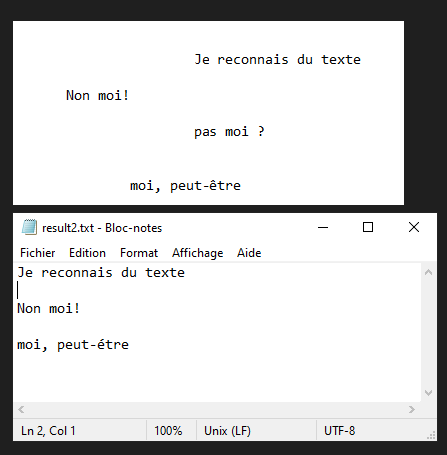
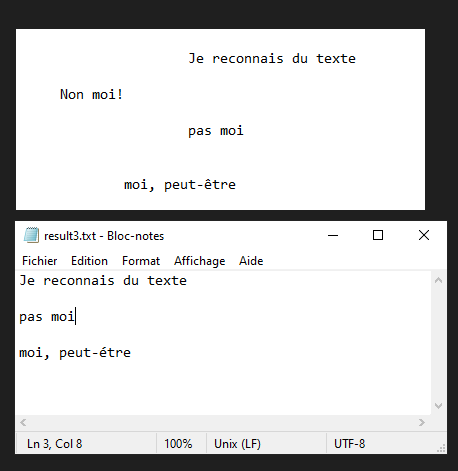
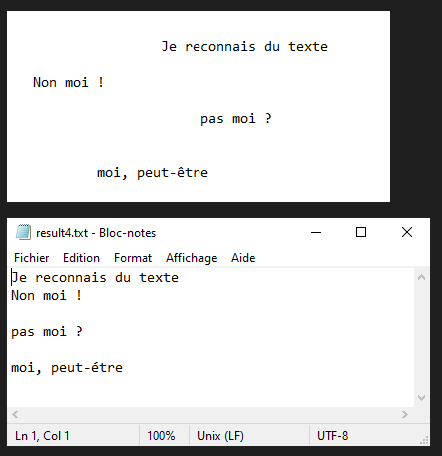
Neste tutorial, vamos ver como reconhecer texto de uma imagem usando Python e Tesseract. O Tesseract é uma ferramenta para reconhecer caracteres, e portanto texto, contidos numa imagem (OCR, Optical Character Recognition).
Instalar o Tesseract
Em Linux
Para instalar o tesseract, introduza os seguintes comandos num terminal
O Tesseract reconhecerá o texto contido na imagem test.png e escreverá o texto em bruto no ficheiro result.txt.
N.B.: O Tesseract pode ter dificuldades com a pontuação e o alinhamento do texto.
Reconhecimento de texto com o Pytesseract
Pode então instalar o pacote pytesseract
pip install pytesseract
A vantagem de utilizar Python, e OpenCV em particular, é que pode processar imagens e implementar a ferramenta em pacotes de software maiores. Segue-se uma lista de algumas das vantagens:
deteção de texto num vídeo
Processamento e filtragem de imagens para caracteres obstruídos, por exemplo
Detetar texto de um ficheiro PDF
Escrever os resultados num ficheiro Word ou Excel
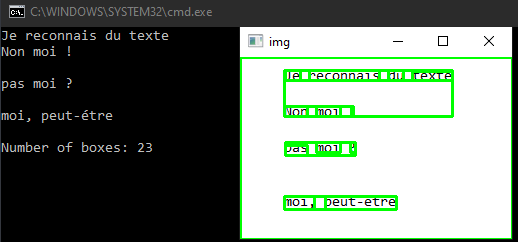
No script seguinte, carregamos a imagem com o OpenCV e desenhamos rectângulos à volta do texto detectado. Os dados de posição são obtidos utilizando a função image_to_data. O texto em bruto pode ser obtido utilizando a função image_to_string
from PIL import Image
import pytesseract
from pytesseract import Output
import cv2
source = 'test.png'
img = cv2.imread(source)
text=pytesseract.image_to_string(img)
print(text)
d = pytesseract.image_to_data(img, output_type=Output.DICT)
NbBox = len(d['level'])
print ("Number of boxes: {}".format(NbBox))
for i in range(NbBox):
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
# display rectangle
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
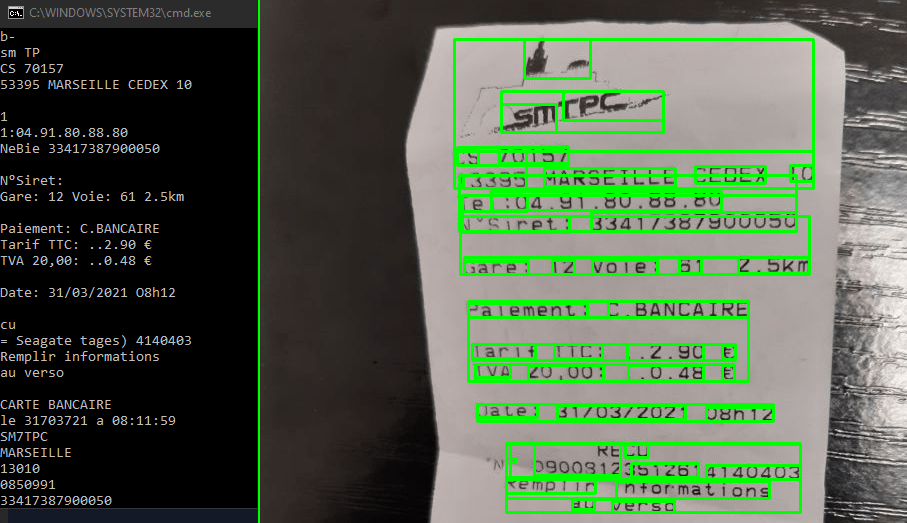
O guião também funciona com fotografias de documentos
Bonus: Reconhecimento de texto com Python à partir d’un fichier PDF
Adicione a pasta bin à variável de ambiente Path (C:\Users\ADMIN\Documents\poppler\Library\bin)
teste com o comando pdftoppm -h
Script para recuperar texto de um PDF
from pdf2image import convert_from_path, convert_from_bytes
from PIL import Image
import pytesseract
from pytesseract import Output
images = convert_from_path('invoice.pdf')
# get text
print("Number of pages: {}".format(len(images)))
for i,img in enumerate(images):
print ("Page N°{}\n".format(i+1))
print(pytesseract.image_to_string(img))
Script para apresentar rectângulos num PDF
from pdf2image import convert_from_path, convert_from_bytes
from PIL import Image
import pytesseract
from pytesseract import Output
import cv2
import numpy
images = convert_from_path('invoice.pdf')
for i,source in enumerate(images):
print ("Page N°{}\n".format(i+1))
#convert PIL to opencv
pil_image = source.convert('RGB')
open_cv_image = numpy.array(pil_image)
# Convert RGB to BGR
img = open_cv_image[:, :, ::-1].copy()
#img = cv2.imread(source)
d = pytesseract.image_to_data(img, output_type=Output.DICT)
NbBox = len(d['level'])
print ("Number of boxes: {}".format(NbBox))
for j in range(NbBox):
(x, y, w, h) = (d['left'][j], d['top'][j], d['width'][j], d['height'][j])
# display rectangle
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Aplicações
Ler documentos digitalizados
Reconhecimento de texto em tempo real a partir de vídeo