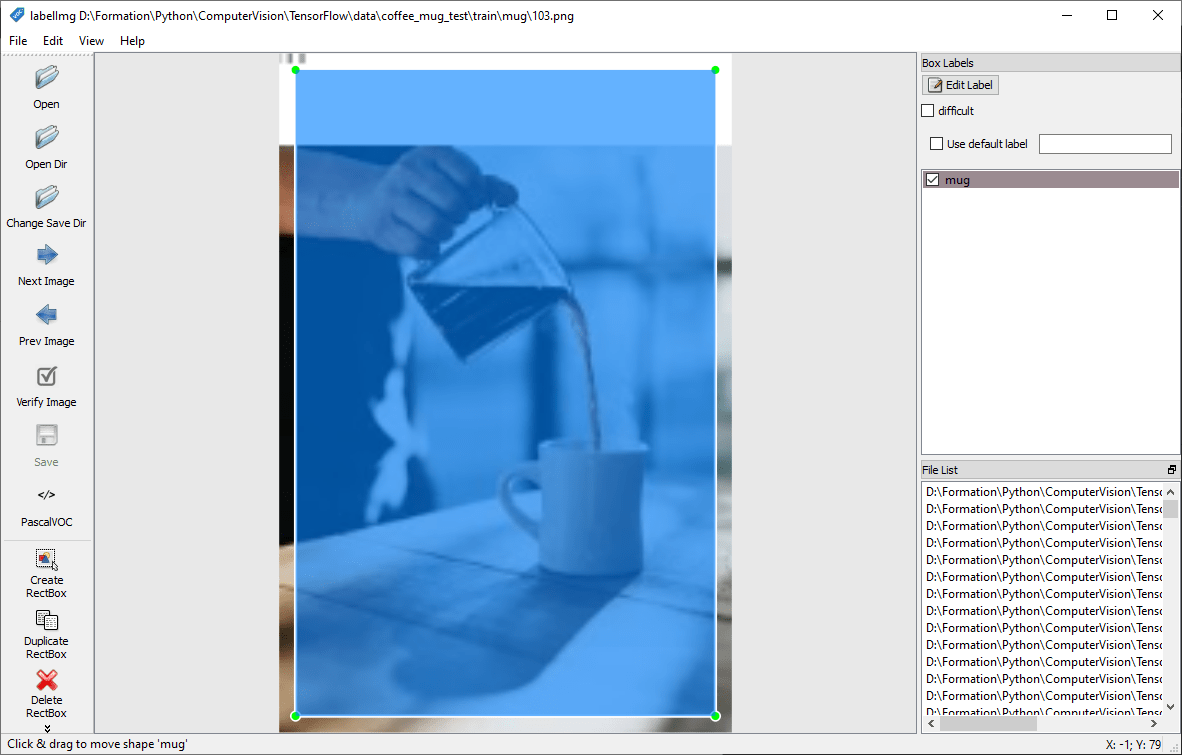
To prepare an image database for training a neural network in object recognition, you need to recognize the images in the database yourself. This means giving them a label and a recognition zone.
This tutorial follows on from the article Creating an image bank.
Preparation objective
The aim is to create datasets that will facilitate training with TensorFlow, Yolo or Keras tools.
There are two ways to do this:
- Use labelImg
- Create a folder architecture and use a script (training with Keras only)
Preparing an image bank with labelImg
You can download and install labelImg
- Linux
python3 -m pip install labelImg labelImg
- Windows
Follow the build instructions on github. You can also find an executable labelImg.exe
Add a box and a label
Launch labelImg and select the folder using the “Open Dir” button.
For each image, surround the object to be detected and assign it a label using the “Create RectBox” button.
N.B.: avoid protruding beyond the image when drawing the box. This can cause problems during training.
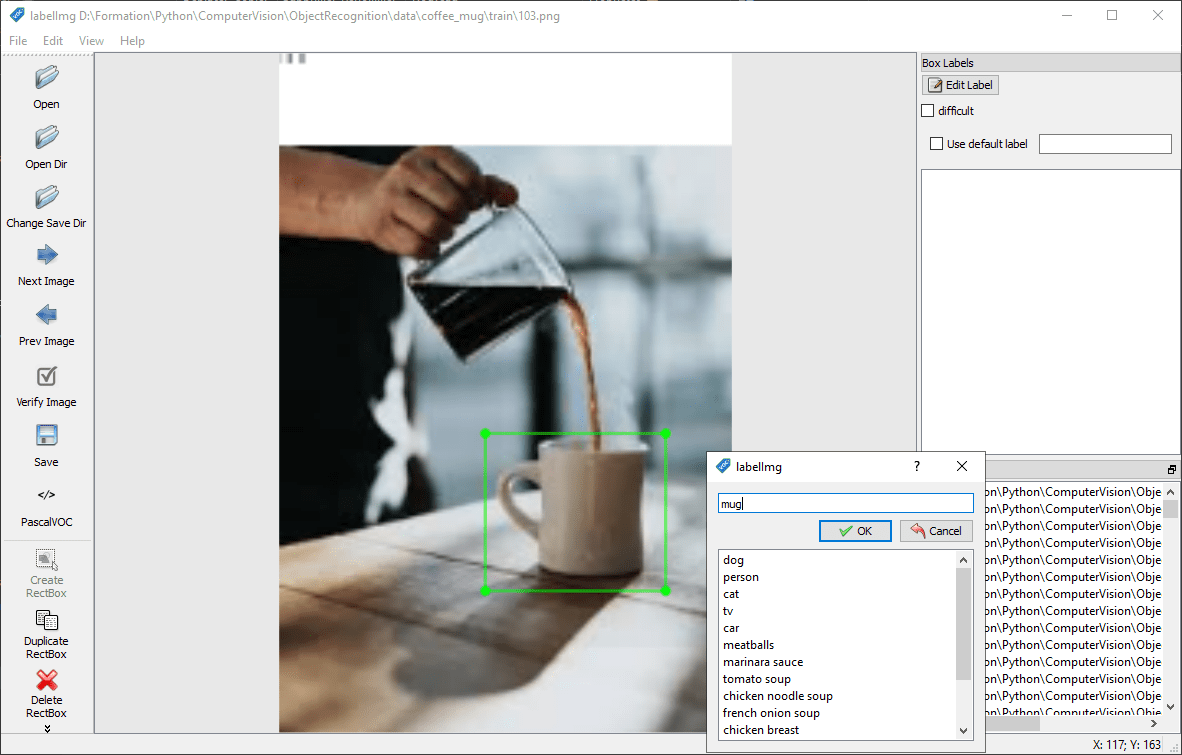
Convert to PascalVOC format
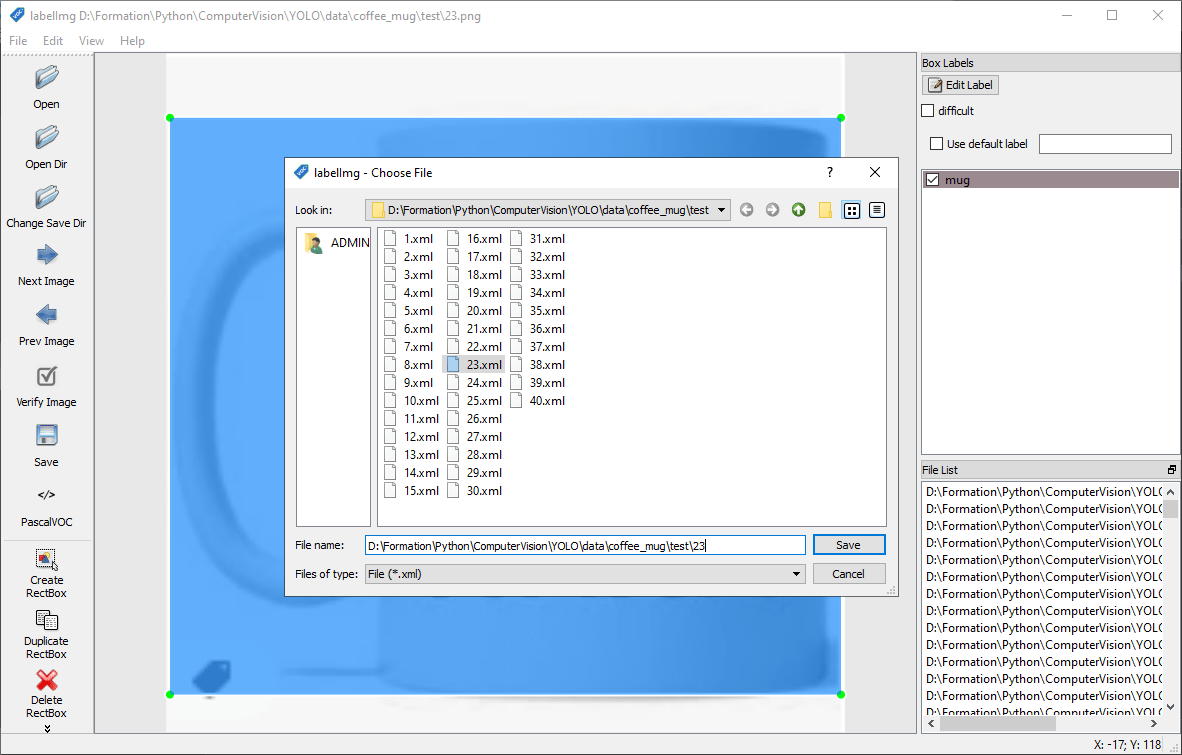
Convert to YOLO format
N.B.: You can save both formats in succession, or save in VOC and convert to YOLO using the convert_voc_to_yolo.py script.
Preparing an image bank with folder architecture
The idea is to place the images in sub-folders named after the class. For training, the image bank should contain between 1 and 3 folders: train, test, validation (the test and validation folders are optional, as they can be created from the first folder).
N.B.: this method requires only one object per image.
- images
- train
- cats
- dogs
- validation
- cats
- dogs
- train
To create files containing name and detection zone info from image folders, you can use the generate_voc_files.py script:
- access paths to the various folders (folders[‘train’
Class names will be defined by folder names, and the detection area by image size.
generate_voc_files.py
import glob
import os
import pickle
import cv2
import xml.etree.ElementTree as ET
import xml.dom.minidom
from os import listdir, getcwd
from os.path import join
dirs = ['train', 'test']
classes = ['mug']
def getImagesInDir(dir_path):
image_list = []
for filename in glob.glob(dir_path + '/**/*.png', recursive=True):
image_list.append(filename)
return image_list
def generate_voc(image_path):
#get image data
dirname=os.path.dirname(image_path)
foldername=dirname.split('\\')[-1]
basename = os.path.basename(image_path)
basename_no_ext = os.path.splitext(basename)[0]
im = cv2.imread(image_path)
h,w,c=im.shape
root = ET.Element('annotation')
folder = ET.SubElement(root, 'folder')
folder.text=foldername
filename = ET.SubElement(root, 'filename')
filename.text=basename
path = ET.SubElement(root, 'path')
path.text=image_path
source = ET.SubElement(root, 'source')
database = ET.SubElement(source, 'database')
database.text = 'Unknown'
size = ET.SubElement(root, 'size')
width = ET.SubElement(size, 'width')
width.text='{}'.format(w)
height = ET.SubElement(size, 'height')
height.text='{}'.format(h)
depth = ET.SubElement(size, 'depth')
depth.text='{}'.format(c)
segmented = ET.SubElement(root, 'segmented')
segmented.text = '0'
objec = ET.SubElement(root, 'object')
name = ET.SubElement(objec, 'name')
name.text=foldername
pose = ET.SubElement(objec, 'pose')
pose.text='Unspecified'
truncated = ET.SubElement(objec, 'truncated')
truncated.text='0'
difficult = ET.SubElement(objec, 'difficult')
difficult.text='0'
bndbox = ET.SubElement(objec, 'bndbox')
xmin = ET.SubElement(bndbox, 'xmin')
xmin.text='{}'.format(0+5)
ymin = ET.SubElement(bndbox, 'ymin')
ymin.text='{}'.format(0+5)
xmax = ET.SubElement(bndbox, 'xmax')
xmax.text='{}'.format(w-5)
ymax = ET.SubElement(bndbox, 'ymax')
ymax.text='{}'.format(h-5)
tree = ET.ElementTree(root)
outxml=join(dirname,basename_no_ext+'.xml')
tree.write(outxml)
return outxml
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(in_file):
dirname=os.path.dirname(in_file)
basename = os.path.basename(in_file)
basename_no_ext = os.path.splitext(basename)[0]
out_file = open(join(dirname, basename_no_ext + '.txt'), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
cwd = getcwd()
for dir_path in dirs:
full_dir_path = join(cwd,dir_path)
image_paths = getImagesInDir(full_dir_path)
for image_path in image_paths:
xml_path=generate_voc(image_path) #generate voc file
convert_annotation(xml_path) #convert to yolo file
print("Finished processing: " + dir_path)
This method quickly produces a database that can be used for training (TensorFlow and Yolo), even if the recognition zone is approximate.
N.B.: Once the XML and TXT files have been created, you can open the lableImg to refine the labels and the detection zone.