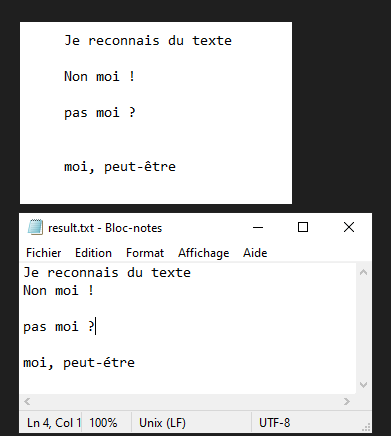
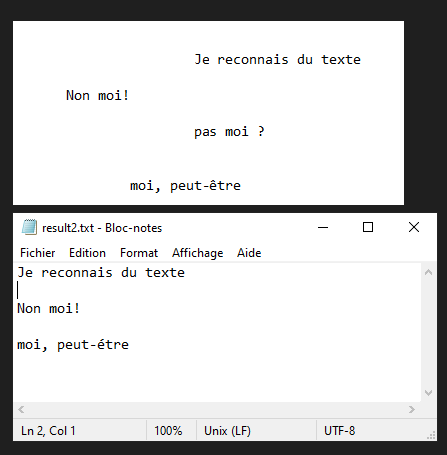
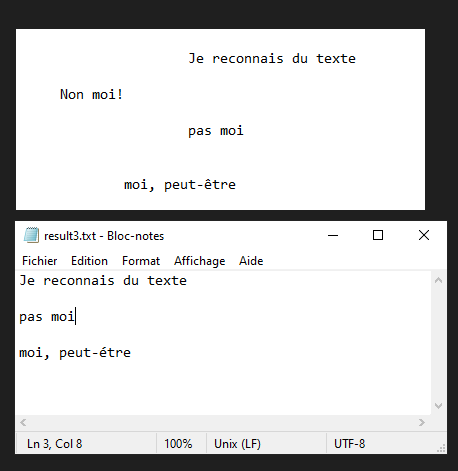
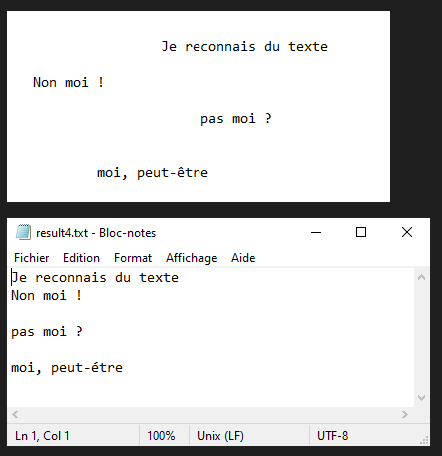
Nous allons voir dans ce tutoriel comment faire de la reconnaissance de texte à partir d’une image avec Python et Tesseract. Tesseract est un outil permettant de reconnaitre des caractères, et donc du texte, contenus dans une image (OCR, Optical Characters Recognition).
Installation de Tesseract
Sous Linux
Pour installer tesseract, entrez les commandes suivantes dans un terminal
Tesseract va reconnaitre le texte contenu dans l’image test.png et écrire le texte brut dans le fichier result.txt
N.B.: Tesseract peut avoir du mal avec la ponctuation et l’alignement du texte
Reconnaissance de texte avec Pytesseract
Vous pouvez ensuite installer le paquet pytesseract
pip install pytesseract
‘L’intérêt d’utiliser Python, et OpenCV particulièrement, est que vous pouvez traiter les images et implémenter l’outil dans un logiciel plus important. Voici une liste de quelques avantages:
détection de texte dans une vidéo
Traitement et filtrage des images dans le cas de caractères obstrués, par exemple
Détecter du texte à partir d’un fichier PDF
Écrire les résultats dans un fichier word ou excel
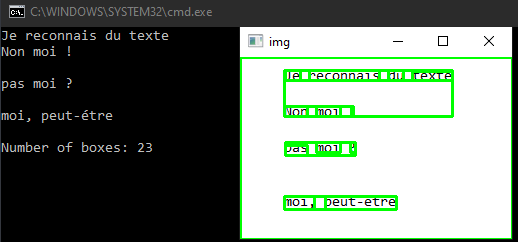
Dans le script suivant, nous chargeons l’image avec OpenCV et nous traçons des rectangles autour du texte détecté. Les données des positions s’obtiennent avec la fonction image_to_data. Il est possible d’obtenir le texte brut avec la fonction image_to_string
from PIL import Image
import pytesseract
from pytesseract import Output
import cv2
source = 'test.png'
img = cv2.imread(source)
text=pytesseract.image_to_string(img)
print(text)
d = pytesseract.image_to_data(img, output_type=Output.DICT)
NbBox = len(d['level'])
print ("Number of boxes: {}".format(NbBox))
for i in range(NbBox):
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
# display rectangle
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
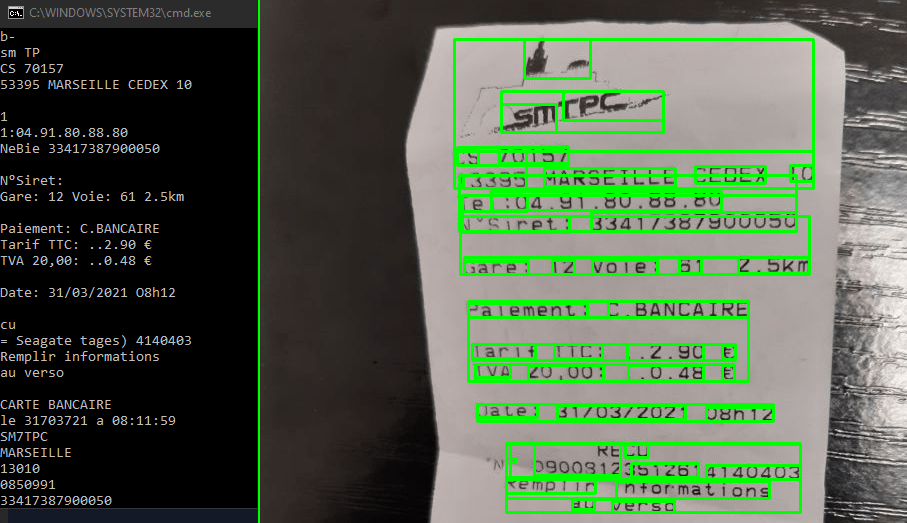
Le script fonctionne aussi sur des photos de document
Bonus: Reconnaissance de texte avec Python à partir d’un fichier PDF
Extraire les fichiers où vous souhaitez (C:/Users/ADMIN/Documents , par exemple)
Ajouter le dossier bin à la variable d’environnement Path (C:\Users\ADMIN\Documents\poppler\Library\bin)
tester avec la commande pdftoppm -h
Script pour récupérer le texte d’un PDF
from pdf2image import convert_from_path, convert_from_bytes
from PIL import Image
import pytesseract
from pytesseract import Output
images = convert_from_path('invoice.pdf')
# get text
print("Number of pages: {}".format(len(images)))
for i,img in enumerate(images):
print ("Page N°{}\n".format(i+1))
print(pytesseract.image_to_string(img))
Script pour afficher les rectangles sur un PDF
from pdf2image import convert_from_path, convert_from_bytes
from PIL import Image
import pytesseract
from pytesseract import Output
import cv2
import numpy
images = convert_from_path('invoice.pdf')
for i,source in enumerate(images):
print ("Page N°{}\n".format(i+1))
#convert PIL to opencv
pil_image = source.convert('RGB')
open_cv_image = numpy.array(pil_image)
# Convert RGB to BGR
img = open_cv_image[:, :, ::-1].copy()
#img = cv2.imread(source)
d = pytesseract.image_to_data(img, output_type=Output.DICT)
NbBox = len(d['level'])
print ("Number of boxes: {}".format(NbBox))
for j in range(NbBox):
(x, y, w, h) = (d['left'][j], d['top'][j], d['width'][j], d['height'][j])
# display rectangle
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Applications
Lire des documents scannés
Faire de la reconnaissance de texte en temps réel à partir d’une vidéo