Pour préparer une banque d’image en vue de l’entrainement d’un réseau de neurones à la reconnaissance d’objet, il faut reconnaitre soit même les images de la base de données. C’est à dire leur donner un label et une zone de reconnaissance.
Ce tutoriel fait suite à l’article créer une banque d’image.
Objectif de la préparation
L’objectif est de créer des jeux de données qui permettront de faciliter l’entrainement avec les outils de TensorFlow, Yolo ou Keras
Pour ce faire, deux choix existent:
- Utiliser labelImg
- Créer une architecture de dossier et utiliser un script (entrainement avec Keras seulement)
Préparer une banque d’image avec labelImg
Vous pouvez télécharger et installer labelImg
- Linux
python3 -m pip install labelImg
labelImg- Windows
Suivez les consignes de construction sur github. Vous pouvez aussi trouver un exécutable labelImg.exe
Ajouter une boite et un label
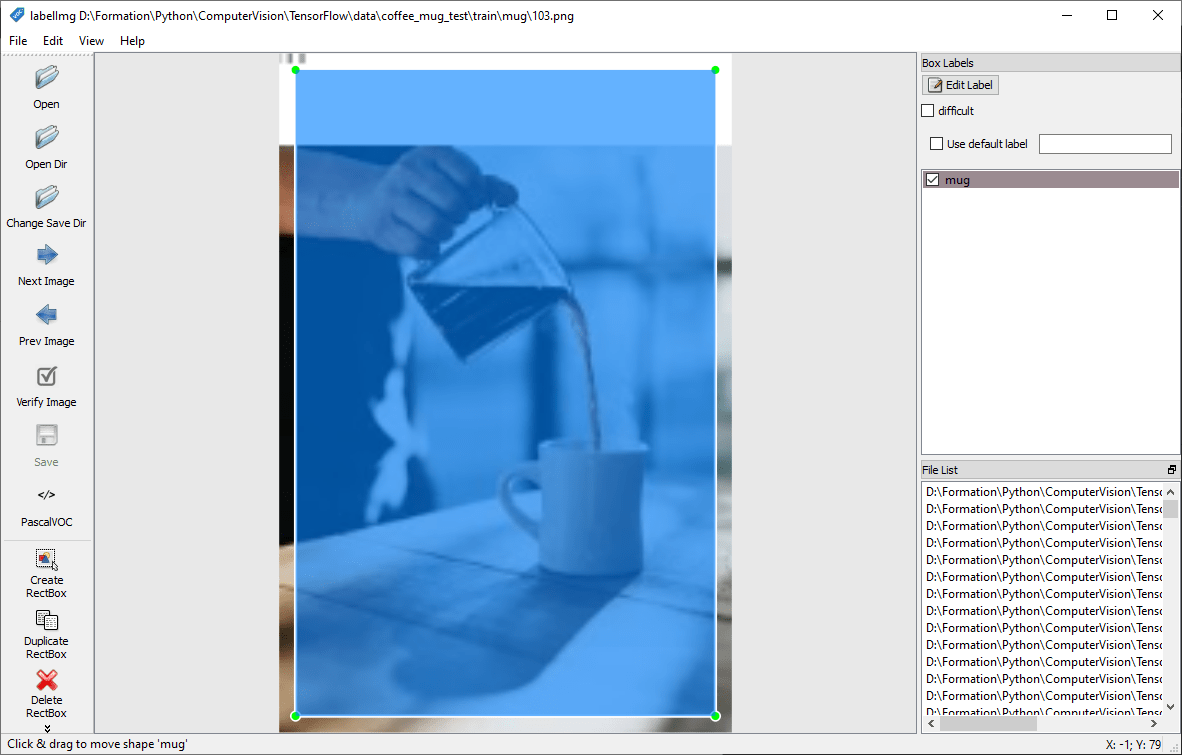
Lancer labelImg et sélectionner le dossier à l’aide du bouton « Open Dir ».
Pour chaque image, vous allez entourer l’objet à détecter et lui affecter un nom (label) à l’aide du bouton « Create RectBox ».
N.B.: évitez de dépasser de l’image lorsque vous dessinez la boîte. Cela peut poser des soucis lors de l’entrainement

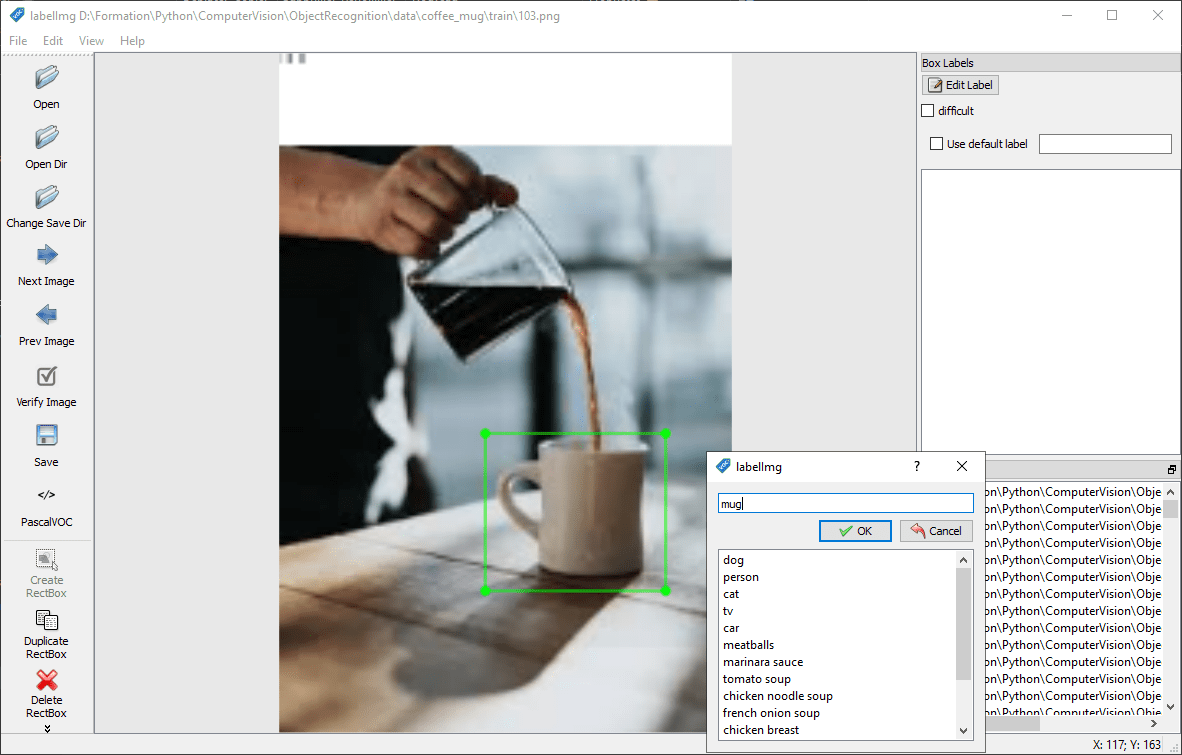
Convertir au format PascalVOC
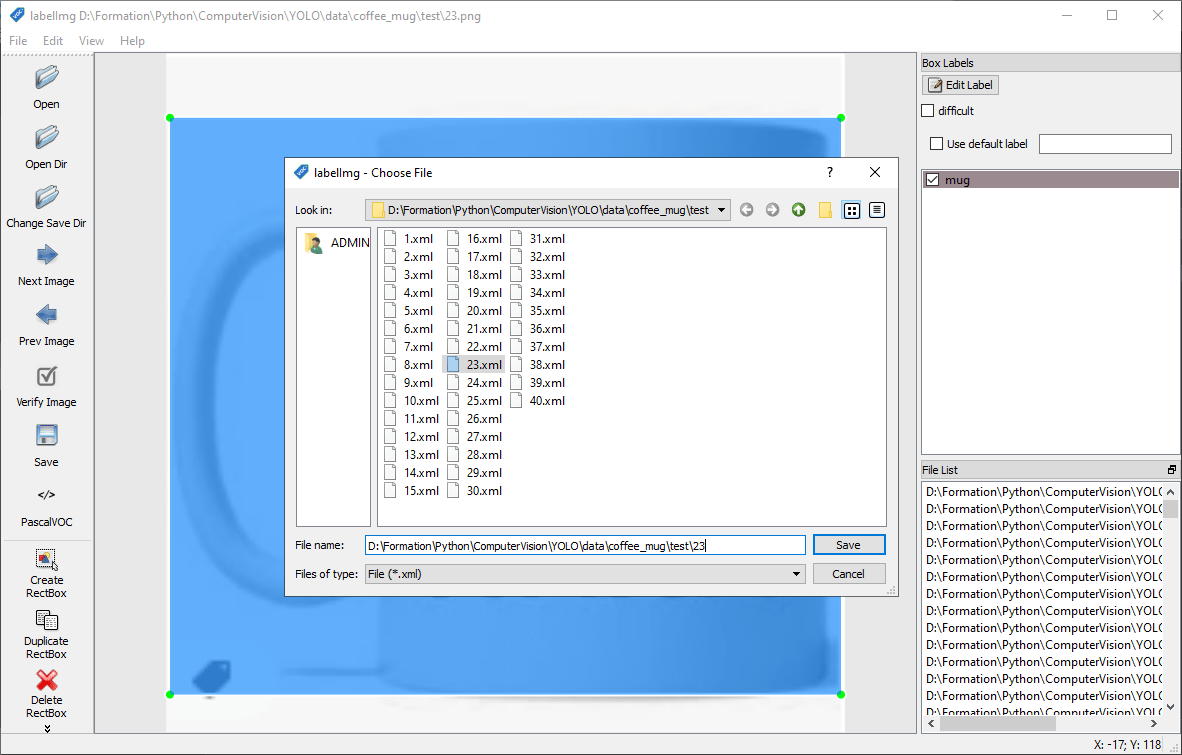
Convertir au format YOLO
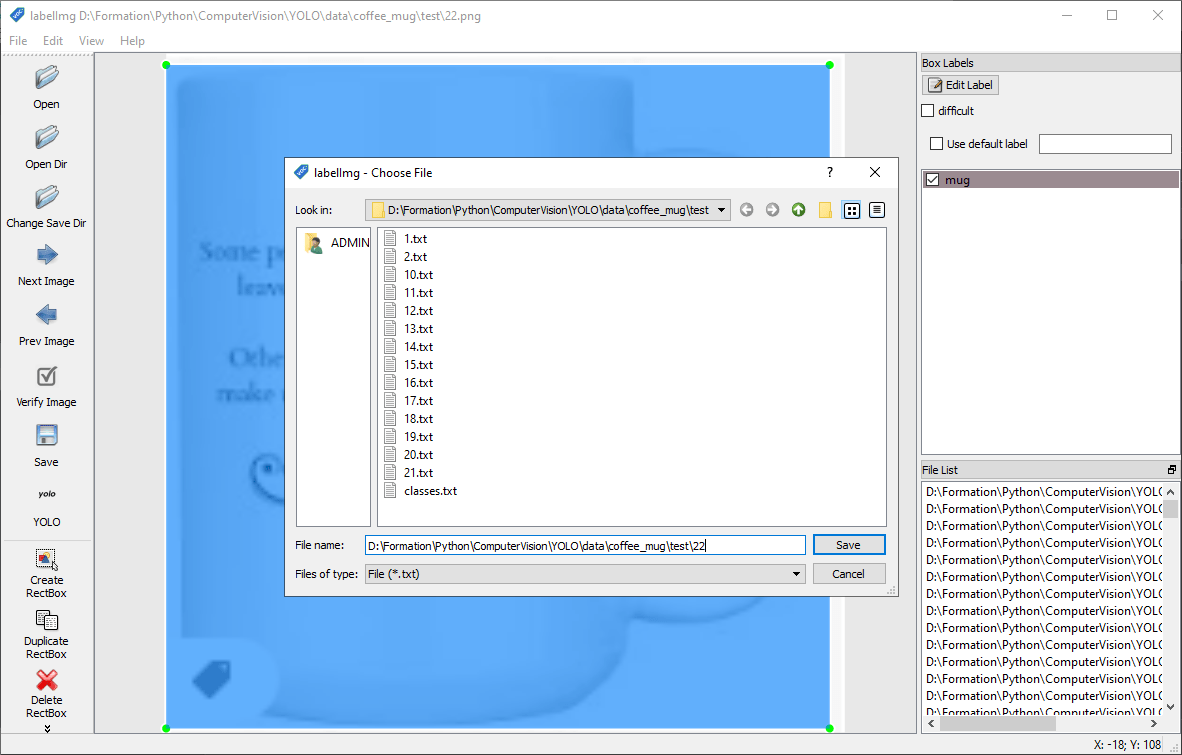
N.B.: Vous pouvez sauvegarder les deux formats à la suite ou sauvegarder en VOC et convertir en YOLO à l’ai du script convert_voc_to_yolo.py
Préparer une banque d’image avec une architecture de dossier
L’idée est de placer les images dans des sous-dossiers du nom de la classe. Pour l’entrainement, la banque d’image doit contenir entre 1 et 3 dossiers: train, test, validation (les dossiers test et validation sont optionnels car ils peuvent être créés à partir du premier
N.B.: pour cette méthode il faut un seul objet par image
- images
- train
- cats
- dogs
- validation
- cats
- dogs
- train
Pour créer les fichiers contenant les info de nom et de zone de détection à partir des dossier images, vous pouvez utiliser le scripts generate_voc_files.py en modifiant:
- les chemins d’accès vers les différents dossiers (folders[‘train’/’validation’/’test’])
Les noms de classe seront définies par les noms de dossier et la zone de détection par la taille des images.
generate_voc_files.py
import glob
import os
import pickle
import cv2
import xml.etree.ElementTree as ET
import xml.dom.minidom
from os import listdir, getcwd
from os.path import join
dirs = ['train', 'test']
classes = ['mug']
def getImagesInDir(dir_path):
image_list = []
for filename in glob.glob(dir_path + '/**/*.png', recursive=True):
image_list.append(filename)
return image_list
def generate_voc(image_path):
#get image data
dirname=os.path.dirname(image_path)
foldername=dirname.split('\\')[-1]
basename = os.path.basename(image_path)
basename_no_ext = os.path.splitext(basename)[0]
im = cv2.imread(image_path)
h,w,c=im.shape
root = ET.Element('annotation')
folder = ET.SubElement(root, 'folder')
folder.text=foldername
filename = ET.SubElement(root, 'filename')
filename.text=basename
path = ET.SubElement(root, 'path')
path.text=image_path
source = ET.SubElement(root, 'source')
database = ET.SubElement(source, 'database')
database.text = 'Unknown'
size = ET.SubElement(root, 'size')
width = ET.SubElement(size, 'width')
width.text='{}'.format(w)
height = ET.SubElement(size, 'height')
height.text='{}'.format(h)
depth = ET.SubElement(size, 'depth')
depth.text='{}'.format(c)
segmented = ET.SubElement(root, 'segmented')
segmented.text = '0'
objec = ET.SubElement(root, 'object')
name = ET.SubElement(objec, 'name')
name.text=foldername
pose = ET.SubElement(objec, 'pose')
pose.text='Unspecified'
truncated = ET.SubElement(objec, 'truncated')
truncated.text='0'
difficult = ET.SubElement(objec, 'difficult')
difficult.text='0'
bndbox = ET.SubElement(objec, 'bndbox')
xmin = ET.SubElement(bndbox, 'xmin')
xmin.text='{}'.format(0+5)
ymin = ET.SubElement(bndbox, 'ymin')
ymin.text='{}'.format(0+5)
xmax = ET.SubElement(bndbox, 'xmax')
xmax.text='{}'.format(w-5)
ymax = ET.SubElement(bndbox, 'ymax')
ymax.text='{}'.format(h-5)
tree = ET.ElementTree(root)
outxml=join(dirname,basename_no_ext+'.xml')
tree.write(outxml)
return outxml
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(in_file):
dirname=os.path.dirname(in_file)
basename = os.path.basename(in_file)
basename_no_ext = os.path.splitext(basename)[0]
out_file = open(join(dirname, basename_no_ext + '.txt'), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
cwd = getcwd()
for dir_path in dirs:
full_dir_path = join(cwd,dir_path)
image_paths = getImagesInDir(full_dir_path)
for image_path in image_paths:
xml_path=generate_voc(image_path) #generate voc file
convert_annotation(xml_path) #convert to yolo file
print("Finished processing: " + dir_path)
Cette méthode permet d’avoir rapidement une base de données exploitable pour l’entrainement (TensorFlow et Yolo) même si la zone de reconnaissance est approximative.
N.B.: Une fois les fichiers XML et TXT créés, vous pouvez ouvrir lableImg pour affiner les labels ainsi que la zone de détection.