Pour récolter des données sur internet, il est possible de créer un Web crawler ou Web scraping avec Python. Un robot d’exploration du Web est un outil qui permet d’extraire des données d’une ou plusieurs pages Web.
Configuration de l’environnement Python
Nous partons du principe que Python3 et pip sont installés sur votre machine. Vous pouvez également utiliser un environnement virtuel pour conserver un projet propre et maitriser les versions de librairies de votre web crawler Python.
Nous allons tout d’abord installer la librairie requests qui permet de faire des requêtes HTTP au serveur pour récupérer les données.
python -m pip install requestsPour analyser et naviguer dans les données du Web, nous utilisons la librairie Beautiful Soup qui permet de travailler avec des scripts à balises comme le HTML ou le XML
python -m pip install beautifulsoup4Enfin, nous installons la librairie Selenium qui permet d’automatiser les tâches d’un navigateur Web. Elle permet d’afficher des pages web dynamiques et de réaliser des actions sur l’interface. Cette librairie permet à elle seule de faire du Web scraping sur internet car elle peut travailler avec un site web dynamique qui fonctionne avec JavaScript.
python -m pip install seleniumPour faire fonctionner Selenium avec Mozilla, vous aurez besoin de télécharger Geckodriver
Récupérer une page Web avec resquest
Imaginons que nous souhaitions récupérer les données techniques d’une carte Arduino, nous pouvons charger la page désirée avec requests et bs4
page = requests.get("https://docs.arduino.cc/hardware/uno-rev3/")
content = BeautifulSoup(page.text, 'html.parser')En observant la structure de la page, vous pouvez repérer les balises, classes, identifiants ou textes qui vous intéressent. Dans cet exemple, nous récupérons
- le nom de la carte
- la description de la carte
N.B.: Vous pouvez retrouver la structure de la page web sur votre navigateur avec clique-droit sur la page puis « Inspecter »
import requests
from bs4 import BeautifulSoup
print("Starting Web Crawling ...")
#website to crawl
website="https://docs.arduino.cc/hardware/uno-rev3/"
#google search
#keywords = ["arduino","datasheet"]
#googlesearch = "https://www.google.com/search?client=firefox-b-d&q="
#search = "+".join(keywords)
#website = googlesearch+search
# get page
page = requests.get(website)
#extract html data
content = BeautifulSoup(page.text, 'html.parser')
# extract tags
h1_elms = content.find_all('h1')
print("Board : ",h1_elms)
#get element by class
description = content.find(class_="product-features__description").text
print("Description : ",description)Starting Web Crawling ...
Board : [<h1>UNO R3</h1>]
Description : Arduino UNO is a microcontroller board based on the ATmega328P. It has 14 digital input/output pins (of which 6 can be used as PWM outputs), 6 analog inputs, a 16 MHz ceramic resonator, a USB connection, a power jack, an ICSP header and a reset button. It contains everything needed to support the microcontroller; simply connect it to a computer with a USB cable or power it with a AC-to-DC adapter or battery to get started. You can tinker with your UNO without worrying too much about doing something wrong, worst case scenario you can replace the chip for a few dollars and start over again.On pourrait imaginer boucler cet opération sur une liste d’URL pour plusieurs cartes.
websites = [
"https://docs.arduino.cc/hardware/uno-rev3/",
"https://docs.arduino.cc/hardware/nano/",
"https://docs.arduino.cc/hardware/mega-2560/",
"https://docs.arduino.cc/hardware/leonardo/",
]Avec cette méthode, on ne peut malheureusement pas charger la liste détaillé des spécification « Tech Specs » pour cela nous devons nous servir du navigateur.
Mettre en place un Web Crawler avec Selenium
Pour charger une page rien de plus facile
from selenium import webdriver
GECKOPATH = "PATH_TO_GECKO"
sys.path.append(GECKOPATH)
print("Starting Web Crawling ...")
#website to crawl
website="https://docs.arduino.cc/hardware/uno-rev3/"
#create browser handler
browser = webdriver.Firefox()
browser.get(website)
#browser.quit()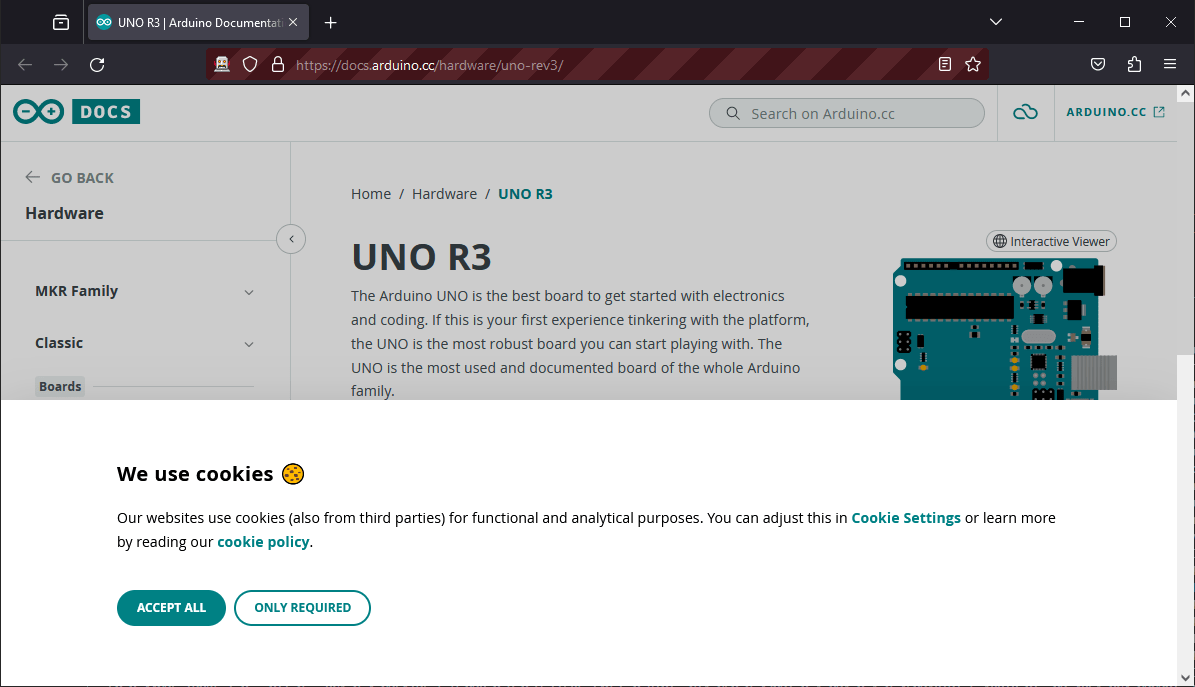
Validation des cookies
En affichant la page, vous aller certainement tomber sur la bannière de cookie qu’il faudra valider ou non pour continuer la navigation. Pour cela, il faut retrouver et cliquer sur le bouton « accepter »
def acceptcookies(): """class="iubenda-cs-accept-btn iubenda-cs-btn-primary""" browser.find_elements(By.CLASS_NAME,"iubenda-cs-accept-btn")[0].click() acceptcookies()
Attente de chargement
Comme la page est affiché dans le navigateur, il faut un certain temps pour qu’elle charge les données et que toutes les balises soient affichées. Pour attendre le chargement, vous pouvez attendre un temps arbitraire
browser.implicitly_wait(10)Ou attendre qu’une balise particulière soit présente comme le bouton d’acceptation des cookies
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
def waitForElement(locator, timeout ):
elm = WebDriverWait(browser, timeout).until(expected_conditions.presence_of_element_located(locator))
return elm
myElem =waitForElement((By.CLASS_NAME , 'iubenda-cs-accept-btn'),30)N.B: Si vous rencontrez d’autre problème (élément inconnu , bouton non cliquable, etc.) dans le script alors qu’il n’y a pas de soucis sur la page Web, n’hésitez pas à utiliser la fonction time.sleep()
Chercher et appuyer sur un élément DOM
Pour afficher les spécifications techniques, le script doit cliquer sur l’onglet ‘Tech Specs’. Il faut donc trouver l’élément à partir du texte. Pour cela, il y a deux méthodes: tester le texte de l’élément ou utiliser Xpath
#get element by text
btn_text = 'Tech Specs'
btn_elms = browser.find_elements(By.CLASS_NAME,'tabs')[0].find_elements(By.TAG_NAME,'button')
for btn in btn_elms:
if btn.text == btn_text:
btn.click()
spec_btn = browser.find_element(By.XPATH, "//*[contains(text(),'Tech Specs')]")
spec_btn.click()Récupérer les données désirées
Une fois la page souhaitée chargée, vous pouvez récupérer les données
Soit toutes les données qui sont affichées sous forme de tableau
#get all rows and children
print("Tech specs")
print("-------------------------------------")
tr_elms = browser.find_elements(By.TAG_NAME,'tr')
for tr in tr_elms:
th_elms = tr.find_elements(By.XPATH, '*')
if len(th_elms)>1:
print(th_elms[0].text, " : ", th_elms[1].text)Soit une donnée spécifique
#get parent and siblings
print("Specific data")
print("-------------------------------------")
data_row = browser.find_element(By.XPATH, "//*[contains(text(),'Main Processor')]")
data = data_row.find_element(By.XPATH, "following-sibling::*[1]").text
print(data_row.text, " : ", data)Résultat du crawling des spécifications
Starting Web Crawling ...
Page is ready!
Tech specs
-------------------------------------
Name : Arduino UNO R3
SKU : A000066
Built-in LED Pin : 13
Digital I/O Pins : 14
Analog input pins : 6
PWM pins : 6
UART : Yes
I2C : Yes
SPI : Yes
I/O Voltage : 5V
Input voltage (nominal) : 7-12V
DC Current per I/O Pin : 20 mA
Power Supply Connector : Barrel Plug
Main Processor : ATmega328P 16 MHz
USB-Serial Processor : ATmega16U2 16 MHz
ATmega328P : 2KB SRAM, 32KB FLASH, 1KB EEPROM
Weight : 25 g
Width : 53.4 mm
Length : 68.6 mm
Specific data
-------------------------------------
Main Processor : ATmega328P 16 MHz
PS D:\Formation\Python\WebCrawler> Récupérer des données sur différentes pages
Une fois que vous maitrisez ces outils et avez une bonne idée des données à récupérer et de la structure des pages Web, vous pouvez scraper des données sur plusieurs pages. Dans ce dernier exemple, nous récupérons les données techniques de différentes cartes Arduino. Pour cela, nous créons une boucle qui va exécuter le code précédent sur une liste de site
websites = [
"https://docs.arduino.cc/hardware/uno-rev3/",
"https://docs.arduino.cc/hardware/nano/",
"https://docs.arduino.cc/hardware/mega-2560/",
"https://docs.arduino.cc/hardware/leonardo/",
]import sys
import time
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
GECKOPATH = "D:\\AranaCorp\\Marketing\\Prospects"
sys.path.append(GECKOPATH)
print("Starting Web Crawling ...")
websites = [
"https://docs.arduino.cc/hardware/uno-rev3/",
"https://docs.arduino.cc/hardware/nano/",
"https://docs.arduino.cc/hardware/mega-2560/",
"https://docs.arduino.cc/hardware/leonardo/",
]
#create browser handler
browser = webdriver.Firefox()#Firefox(firefox_binary=binary)
def acceptcookies():
#class="iubenda-cs-accept-btn iubenda-cs-btn-primary
browser.find_elements(By.CLASS_NAME,"iubenda-cs-accept-btn")[0].click()
def waitForElement(locator, timeout ):
elm = WebDriverWait(browser, timeout).until(expected_conditions.presence_of_element_located(locator))
return elm
cookie_accepted=False
for website in websites:
browser.get(website)
time.sleep(2)
if not cookie_accepted: #accept cookie once
myElem =waitForElement((By.CLASS_NAME , 'iubenda-cs-accept-btn'),30)
print("Page is ready!")
acceptcookies()
cookie_accepted = True
else:
myElem =waitForElement((By.CLASS_NAME , 'tabs__item'),30)
#get board name
name = browser.find_element(By.TAG_NAME,'h1').text
#get tab Tech Specs
btn_text = 'Tech Specs'
spec_btn = WebDriverWait(browser, 20).until(expected_conditions.element_to_be_clickable((By.XPATH, "//*[contains(text(),'{}')]".format(btn_text))))
spec_btn.click()
#browser.execute_script("arguments[0].click();", spec_btn) #use script to click
#get all rows and children
print(name+" "+btn_text)
print("-------------------------------------")
tr_elms = browser.find_elements(By.TAG_NAME,'tr')
for tr in tr_elms:
th_elms = tr.find_elements(By.XPATH, '*')
if len(th_elms)>1:
print(th_elms[0].text, " : ", th_elms[1].text)
#get parent and siblings
print("Specific data")
print("-------------------------------------")
try:
data_row = browser.find_element(By.XPATH, "//*[contains(text(),'Main Processor')]")
except:
data_row = browser.find_element(By.XPATH, "//*[contains(text(),'Processor')]")
data = data_row.find_element(By.XPATH, "following-sibling::*[1]").text
print(data_row.text, " : ", data)
browser.quit()Starting Web Crawling ...
Page is ready!
UNO R3 Tech Specs
-------------------------------------
Main Processor : ATmega328P 16 MHz
Nano Tech Specs
-------------------------------------
Processor : ATmega328 16 MHz
Mega 2560 Rev3 Tech Specs
-------------------------------------
Main Processor : ATmega2560 16 MHz
Leonardo Tech Specs
-------------------------------------
Processor : ATmega32U4 16 MHzCombiner Selenium et BeautifulSoup
Il est possible de combiner les deux librairies afin de vous apporter toutes leurs fonctionnalités
from bs4 import BeautifulSoup from selenium import webdriver browser = webdriver.Firefox() browser.get(website) html = browser.page_source content = BeautifulSoup(html, 'lxml') browser.quit()
Applications
- Automatiser des tâches de relevée de données sur le Web
- Créer votre banque d’image pour l’entrainement de réseau de neurone
- Trouver des prospect
- Faire un étude de marché