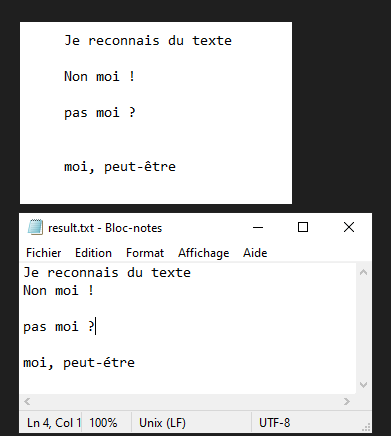
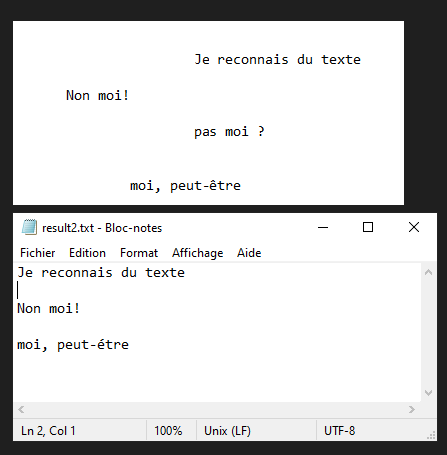
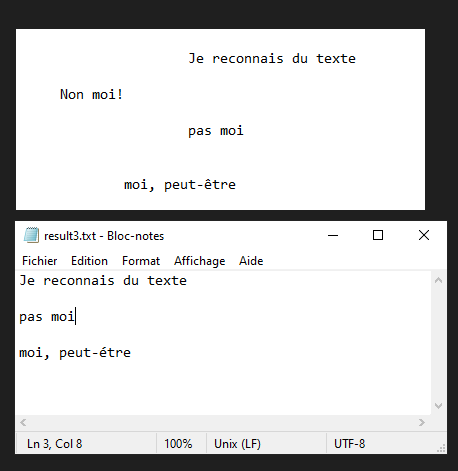
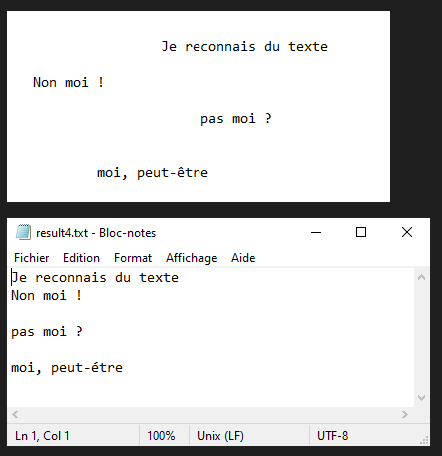
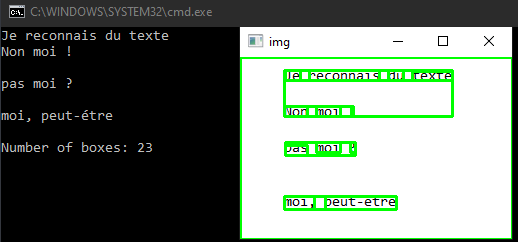
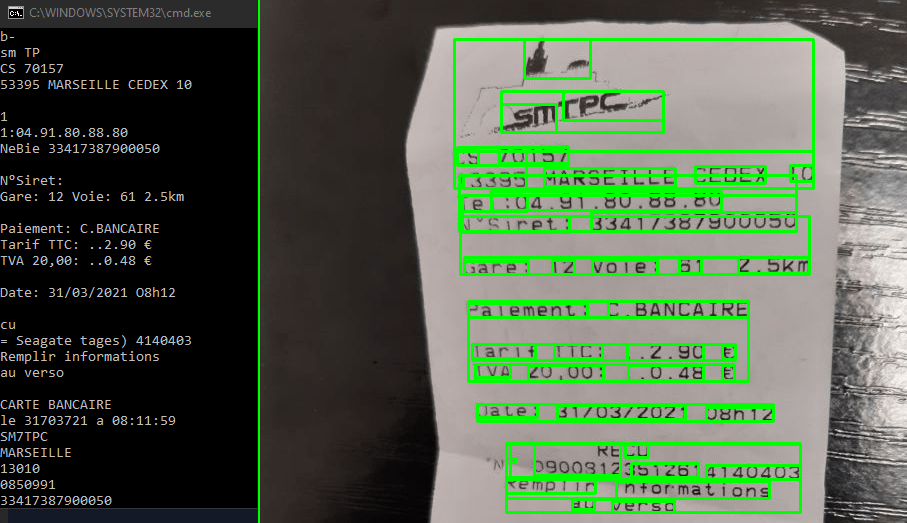
En este tutorial veremos cómo reconocer texto de una imagen utilizando Python y Tesseract. Tesseract es una herramienta para reconocer caracteres, y por tanto texto, contenidos en una imagen (OCR, Optical Character Recognition).
Instalación de Tesseract
En Linux
Para instalar tesseract, introduzca los siguientes comandos en un terminal
Tesseract reconocerá el texto contenido en la imagen test.png y escribirá el texto sin procesar en el archivo result.txt.
Nota: Tesseract puede tener dificultades con la puntuación y la alineación del texto.
Reconocimiento de textos con Pytesseract
A continuación, puede instalar el paquete pytesseract
pip install pytesseract
La ventaja de utilizar Python, y OpenCV en particular, es que puedes procesar imágenes e implementar la herramienta en paquetes de software más grandes. He aquí una lista de algunas de las ventajas:
detección de texto en un vídeo
Tratamiento y filtrado de imágenes para caracteres obstruidos, por ejemplo
Detectar texto de un archivo PDF
Escribir los resultados en un archivo Word o Excel
En el siguiente script, cargamos la imagen con OpenCV y dibujamos rectángulos alrededor del texto detectado. Los datos de posición se obtienen utilizando la función image_to_data. El texto en bruto se obtiene utilizando la función image_to_string
from PIL import Image
import pytesseract
from pytesseract import Output
import cv2
source = 'test.png'
img = cv2.imread(source)
text=pytesseract.image_to_string(img)
print(text)
d = pytesseract.image_to_data(img, output_type=Output.DICT)
NbBox = len(d['level'])
print ("Number of boxes: {}".format(NbBox))
for i in range(NbBox):
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
# display rectangle
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
El script también funciona con fotos de documentos
Bonus: Reconocimiento de textos con Python à partir d’un fichier PDF
Añade la carpeta bin a la variable de entorno Path (C:³³Users³ADMIN³Documents³poppler³Library³bin)
prueba con el comando pdftoppm -h
Script para recuperar texto de un PDF
from pdf2image import convert_from_path, convert_from_bytes
from PIL import Image
import pytesseract
from pytesseract import Output
images = convert_from_path('invoice.pdf')
# get text
print("Number of pages: {}".format(len(images)))
for i,img in enumerate(images):
print ("Page N°{}\n".format(i+1))
print(pytesseract.image_to_string(img))
Script para mostrar rectángulos en un PDF
from pdf2image import convert_from_path, convert_from_bytes
from PIL import Image
import pytesseract
from pytesseract import Output
import cv2
import numpy
images = convert_from_path('invoice.pdf')
for i,source in enumerate(images):
print ("Page N°{}\n".format(i+1))
#convert PIL to opencv
pil_image = source.convert('RGB')
open_cv_image = numpy.array(pil_image)
# Convert RGB to BGR
img = open_cv_image[:, :, ::-1].copy()
#img = cv2.imread(source)
d = pytesseract.image_to_data(img, output_type=Output.DICT)
NbBox = len(d['level'])
print ("Number of boxes: {}".format(NbBox))
for j in range(NbBox):
(x, y, w, h) = (d['left'][j], d['top'][j], d['width'][j], d['height'][j])
# display rectangle
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Aplicaciones
Lectura de documentos escaneados
Reconocimiento de texto en tiempo real a partir de vídeo