Para recopilar datos en Internet, puedes crear un Web crawler o Web scraping con Python. Un rastreador web es una herramienta que extrae datos de una o varias páginas web.
Configuración del entorno Python
Asumimos que Python3 y pip están instalados en tu máquina. También puedes usar un entorno virtual para mantener tu proyecto limpio y controlar las versiones de las librerías de tu rastreador web Python.
Primero vamos a instalar la librería requests, que permite realizar peticiones HTTP al servidor para recuperar datos.
python -m pip install requests
Para analizar y navegar por los datos de la Web, utilizamos la biblioteca Beautiful Soup, que nos permite trabajar con scripts utilizando etiquetas como HTML o XML.
python -m pip install beautifulsoup4
Por último, vamos a instalar la biblioteca Selenium, que automatiza las tareas del navegador web. Se puede utilizar para mostrar páginas web dinámicas y realizar acciones en la interfaz. Esta biblioteca por sí sola se puede utilizar para el web scraping en Internet, ya que puede trabajar con un sitio web dinámico que utiliza JavaScript.
python -m pip install selenium
Para que Selenium funcione con Mozilla, deberá descargar Geckodriver
Recuperar una página web con resquest
Si queremos recuperar los datos técnicos de una placa Arduino, podemos cargar la página que queramos usando requests y bs4
page = requests.get("https://docs.arduino.cc/hardware/uno-rev3/")
content = BeautifulSoup(page.text, 'html.parser')Observando la estructura de la página, puede identificar las etiquetas, clases, identificadores o textos que le interesen. En este ejemplo, recuperamos
- el nombre de la tarjeta
- descripción de la tarjeta
Nota: Puede ver la estructura de la página web en su navegador haciendo clic con el botón derecho del ratón en la página y seleccionando «Inspeccionar».
import requests
from bs4 import BeautifulSoup
print("Starting Web Crawling ...")
#website to crawl
website="https://docs.arduino.cc/hardware/uno-rev3/"
#google search
#keywords = ["arduino","datasheet"]
#googlesearch = "https://www.google.com/search?client=firefox-b-d&q="
#search = "+".join(keywords)
#website = googlesearch+search
# get page
page = requests.get(website)
#extract html data
content = BeautifulSoup(page.text, 'html.parser')
# extract tags
h1_elms = content.find_all('h1')
print("Board : ",h1_elms)
#get element by class
description = content.find(class_="product-features__description").text
print("Description : ",description)Starting Web Crawling ... Board : [<h1>UNO R3</h1>] Description : Arduino UNO is a microcontroller board based on the ATmega328P. It has 14 digital input/output pins (of which 6 can be used as PWM outputs), 6 analog inputs, a 16 MHz ceramic resonator, a USB connection, a power jack, an ICSP header and a reset button. It contains everything needed to support the microcontroller; simply connect it to a computer with a USB cable or power it with a AC-to-DC adapter or battery to get started. You can tinker with your UNO without worrying too much about doing something wrong, worst case scenario you can replace the chip for a few dollars and start over again.
Esta operación podría completarse con una lista de URL de varias tarjetas.
websites = [
"https://docs.arduino.cc/hardware/uno-rev3/",
"https://docs.arduino.cc/hardware/nano/",
"https://docs.arduino.cc/hardware/mega-2560/",
"https://docs.arduino.cc/hardware/leonardo/",
]Lamentablemente, este método no nos permite cargar la lista detallada de especificaciones «Tech Specs», por lo que tenemos que utilizar el navegador.
Configuración de un rastreador web con Selenium
Cargar una página es fácil
from selenium import webdriver
GECKOPATH = "PATH_TO_GECKO"
sys.path.append(GECKOPATH)
print("Starting Web Crawling ...")
#website to crawl
website="https://docs.arduino.cc/hardware/uno-rev3/"
#create browser handler
browser = webdriver.Firefox()
browser.get(website)
#browser.quit()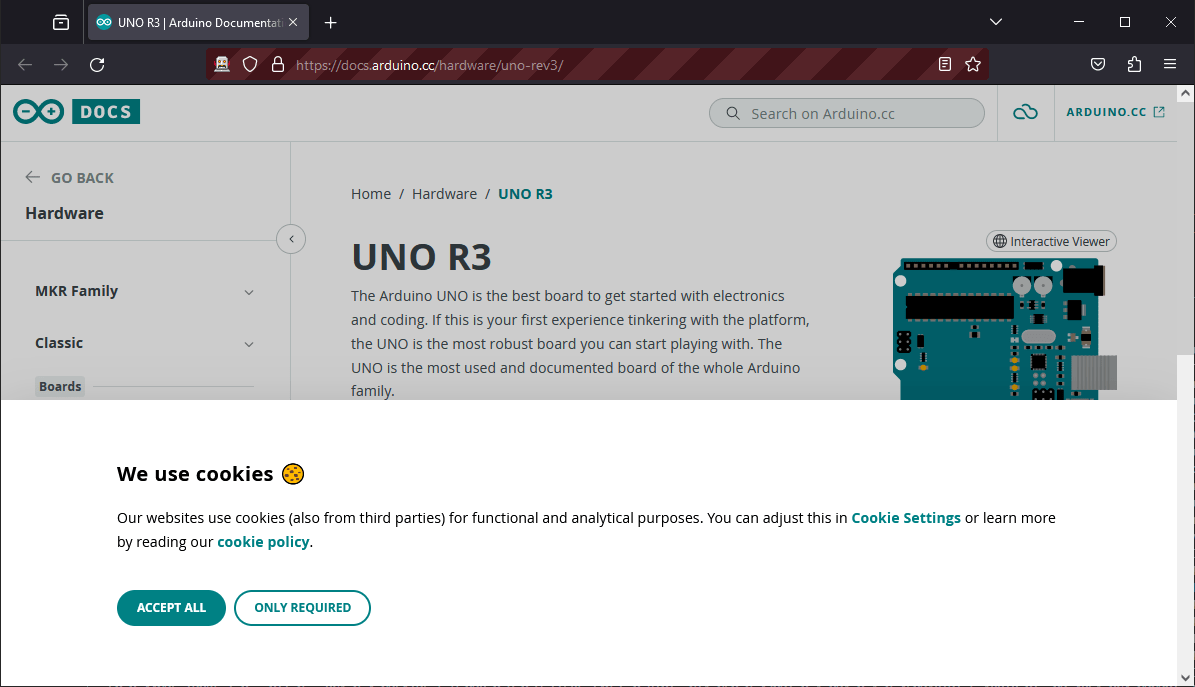
Validación de cookies
Cuando aparezca la página, es probable que te encuentres con el banner de cookies, que deberás aceptar o rechazar para poder seguir navegando. Para ello, busque y haga clic en el botón «aceptar».
def acceptcookies(): """class="iubenda-cs-accept-btn iubenda-cs-btn-primary""" browser.find_elements(By.CLASS_NAME,"iubenda-cs-accept-btn")[0].click() acceptcookies()
Esperando para cargar
Cuando la página se muestra en el navegador, tarda algún tiempo en cargar los datos y en mostrar todas las etiquetas. Para esperar a que se cargue la página, puede esperar un tiempo arbitrario
browser.implicitly_wait(10)
O espere hasta que una etiqueta en particular esté presente, como el botón de aceptación de cookies
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
def waitForElement(locator, timeout ):
elm = WebDriverWait(browser, timeout).until(expected_conditions.presence_of_element_located(locator))
return elm
myElem =waitForElement((By.CLASS_NAME , 'iubenda-cs-accept-btn'),30)N.B: Si encuentras cualquier otro problema (elemento desconocido, botón no clicable, etc.) en el script cuando no hay problemas en la página web, no dudes en utilizar la función time.sleep().
Buscar y pulsar un elemento DOM
Para mostrar las especificaciones técnicas, el script debe hacer clic en la pestaña «Especificaciones técnicas». A continuación, debe encontrar el elemento a partir del texto. Hay dos maneras de hacerlo: probar el texto del elemento o utilizar Xpath
#get element by text
btn_text = 'Tech Specs'
btn_elms = browser.find_elements(By.CLASS_NAME,'tabs')[0].find_elements(By.TAG_NAME,'button')
for btn in btn_elms:
if btn.text == btn_text:
btn.click()
spec_btn = browser.find_element(By.XPATH, "//*[contains(text(),'Tech Specs')]")
spec_btn.click()Recuperar los datos deseados
Una vez cargada la página que desea, puede recuperar los datos
Todos los datos en forma de tabla
#get all rows and children
print("Tech specs")
print("-------------------------------------")
tr_elms = browser.find_elements(By.TAG_NAME,'tr')
for tr in tr_elms:
th_elms = tr.find_elements(By.XPATH, '*')
if len(th_elms)>1:
print(th_elms[0].text, " : ", th_elms[1].text)Datos específicos
#get parent and siblings
print("Specific data")
print("-------------------------------------")
data_row = browser.find_element(By.XPATH, "//*[contains(text(),'Main Processor')]")
data = data_row.find_element(By.XPATH, "following-sibling::*[1]").text
print(data_row.text, " : ", data)Resultado del rastreo de especificaciones
Starting Web Crawling ... Page is ready! Tech specs ------------------------------------- Name : Arduino UNO R3 SKU : A000066 Built-in LED Pin : 13 Digital I/O Pins : 14 Analog input pins : 6 PWM pins : 6 UART : Yes I2C : Yes SPI : Yes I/O Voltage : 5V Input voltage (nominal) : 7-12V DC Current per I/O Pin : 20 mA Power Supply Connector : Barrel Plug Main Processor : ATmega328P 16 MHz USB-Serial Processor : ATmega16U2 16 MHz ATmega328P : 2KB SRAM, 32KB FLASH, 1KB EEPROM Weight : 25 g Width : 53.4 mm Length : 68.6 mm Specific data ------------------------------------- Main Processor : ATmega328P 16 MHz PS D:\Formation\Python\WebCrawler>
Recuperación de datos de diferentes páginas
Una vez que domines estas herramientas y tengas una buena idea de los datos a recuperar y de la estructura de las páginas web, podrás raspar datos de varias páginas. En este último ejemplo, estamos recuperando datos técnicos de varias placas Arduino. Para ello, creamos un bucle que ejecutará el código anterior en una lista de sitios
websites = [
"https://docs.arduino.cc/hardware/uno-rev3/",
"https://docs.arduino.cc/hardware/nano/",
"https://docs.arduino.cc/hardware/mega-2560/",
"https://docs.arduino.cc/hardware/leonardo/",
]import sys
import time
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
GECKOPATH = "D:\\AranaCorp\\Marketing\\Prospects"
sys.path.append(GECKOPATH)
print("Starting Web Crawling ...")
websites = [
"https://docs.arduino.cc/hardware/uno-rev3/",
"https://docs.arduino.cc/hardware/nano/",
"https://docs.arduino.cc/hardware/mega-2560/",
"https://docs.arduino.cc/hardware/leonardo/",
]
#create browser handler
browser = webdriver.Firefox()#Firefox(firefox_binary=binary)
def acceptcookies():
#class="iubenda-cs-accept-btn iubenda-cs-btn-primary
browser.find_elements(By.CLASS_NAME,"iubenda-cs-accept-btn")[0].click()
def waitForElement(locator, timeout ):
elm = WebDriverWait(browser, timeout).until(expected_conditions.presence_of_element_located(locator))
return elm
cookie_accepted=False
for website in websites:
browser.get(website)
time.sleep(2)
if not cookie_accepted: #accept cookie once
myElem =waitForElement((By.CLASS_NAME , 'iubenda-cs-accept-btn'),30)
print("Page is ready!")
acceptcookies()
cookie_accepted = True
else:
myElem =waitForElement((By.CLASS_NAME , 'tabs__item'),30)
#get board name
name = browser.find_element(By.TAG_NAME,'h1').text
#get tab Tech Specs
btn_text = 'Tech Specs'
spec_btn = WebDriverWait(browser, 20).until(expected_conditions.element_to_be_clickable((By.XPATH, "//*[contains(text(),'{}')]".format(btn_text))))
spec_btn.click()
#browser.execute_script("arguments[0].click();", spec_btn) #use script to click
#get all rows and children
print(name+" "+btn_text)
print("-------------------------------------")
tr_elms = browser.find_elements(By.TAG_NAME,'tr')
for tr in tr_elms:
th_elms = tr.find_elements(By.XPATH, '*')
if len(th_elms)>1:
print(th_elms[0].text, " : ", th_elms[1].text)
#get parent and siblings
print("Specific data")
print("-------------------------------------")
try:
data_row = browser.find_element(By.XPATH, "//*[contains(text(),'Main Processor')]")
except:
data_row = browser.find_element(By.XPATH, "//*[contains(text(),'Processor')]")
data = data_row.find_element(By.XPATH, "following-sibling::*[1]").text
print(data_row.text, " : ", data)
browser.quit()Starting Web Crawling ... Page is ready! UNO R3 Tech Specs ------------------------------------- Main Processor : ATmega328P 16 MHz Nano Tech Specs ------------------------------------- Processor : ATmega328 16 MHz Mega 2560 Rev3 Tech Specs ------------------------------------- Main Processor : ATmega2560 16 MHz Leonardo Tech Specs ------------------------------------- Processor : ATmega32U4 16 MHz
Combinación de Selenium y BeautifulSoup
Las dos bibliotecas pueden combinarse para ofrecerte todas sus funciones
from bs4 import BeautifulSoup from selenium import webdriver browser = webdriver.Firefox() browser.get(website) html = browser.page_source content = BeautifulSoup(html, 'lxml') browser.quit()
Aplicaciones
- Automatice las tareas de recogida de datos en la Web
- Cree su banco de imágenes para el entrenamiento de la red neuronal
- Encontrar clientes potenciales
- Realización de estudios de mercado



