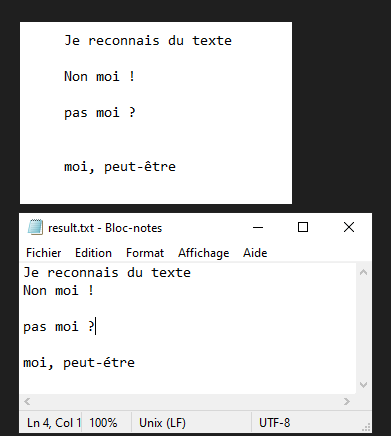
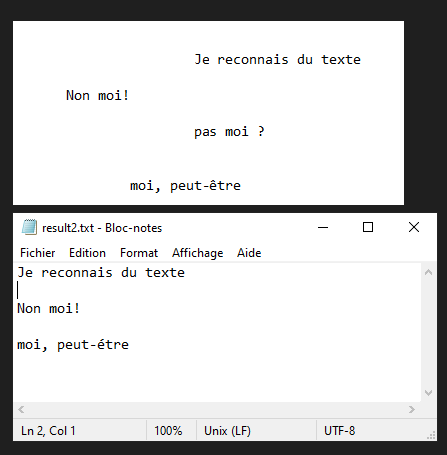
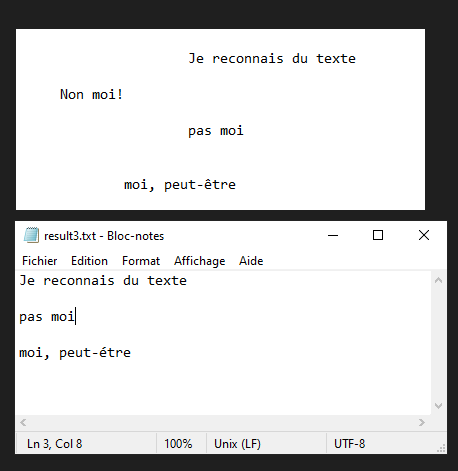
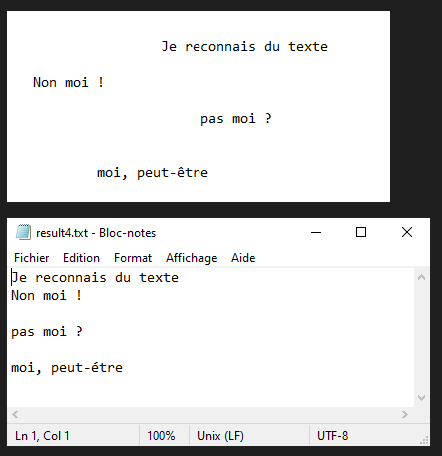
In this tutorial, we’ll look at how to recognize text from images using Python and Tesseract. Tesseract is a tool for recognizing characters, and therefore text, contained in an image (OCR, Optical Character Recognition).
Installing Tesseract
Under Linux
To install tesseract, enter the following commands in a terminal
Tesseract will recognize the text contained in the test.png image and write the raw text to the result.txt file.
N.B.: Tesseract may have difficulty with punctuation and text alignment.
Text recognition with Pytesseract
You can then install the pytesseract package
pip install pytesseract
‘The beauty of using Python, and OpenCV in particular, is that you can process images and implement the tool in larger software. Here’s a list of some of the advantages:
text detection in video
Image processing and filtering for obstructed characters, for example
Detect text from a PDF file
Write the results in a Word or Excel file
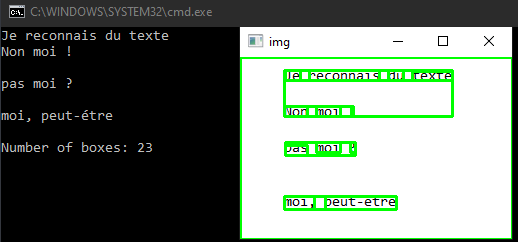
In the following script, we load the image with OpenCV and draw rectangles around the detected text. Position data is obtained using the image_to_data function. The raw text can also be obtained using the image_to_string function.
from PIL import Image
import pytesseract
from pytesseract import Output
import cv2
source = 'test.png'
img = cv2.imread(source)
text=pytesseract.image_to_string(img)
print(text)
d = pytesseract.image_to_data(img, output_type=Output.DICT)
NbBox = len(d['level'])
print ("Number of boxes: {}".format(NbBox))
for i in range(NbBox):
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
# display rectangle
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
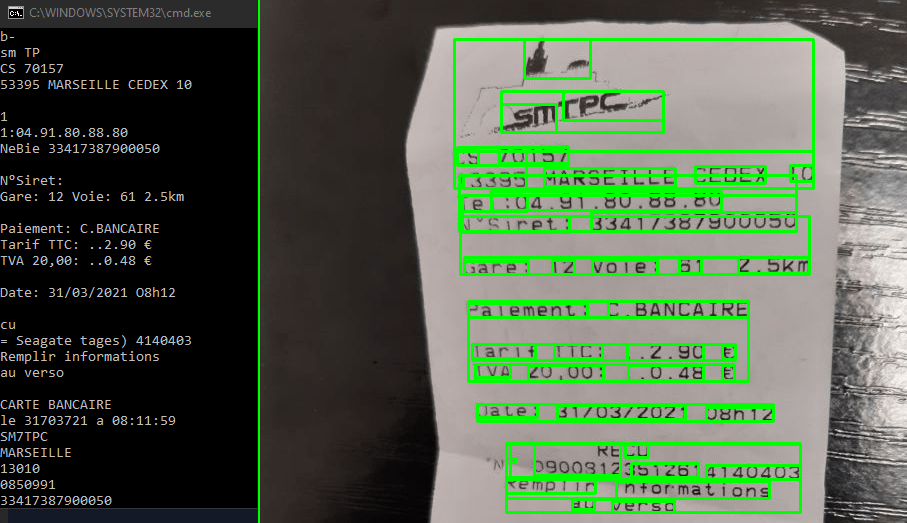
The script also works on document photos
Bonus: Text recognition with Python à partir d’un fichier PDF
Add bin folder to Path environment variable (C:\Users\ADMIN\Documents\poppler\Library\bin)
test with the command pdftoppm -h
Script to retrieve text from a PDF
from pdf2image import convert_from_path, convert_from_bytes
from PIL import Image
import pytesseract
from pytesseract import Output
images = convert_from_path('invoice.pdf')
# get text
print("Number of pages: {}".format(len(images)))
for i,img in enumerate(images):
print ("Page N°{}\n".format(i+1))
print(pytesseract.image_to_string(img))
Script to display rectangles on a PDF
from pdf2image import convert_from_path, convert_from_bytes
from PIL import Image
import pytesseract
from pytesseract import Output
import cv2
import numpy
images = convert_from_path('invoice.pdf')
for i,source in enumerate(images):
print ("Page N°{}\n".format(i+1))
#convert PIL to opencv
pil_image = source.convert('RGB')
open_cv_image = numpy.array(pil_image)
# Convert RGB to BGR
img = open_cv_image[:, :, ::-1].copy()
#img = cv2.imread(source)
d = pytesseract.image_to_data(img, output_type=Output.DICT)
NbBox = len(d['level'])
print ("Number of boxes: {}".format(NbBox))
for j in range(NbBox):
(x, y, w, h) = (d['left'][j], d['top'][j], d['width'][j], d['height'][j])
# display rectangle
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()