, ,
Para treinar uma rede neural na deteção e reconhecimento de objectos, é necessário um banco de imagens para trabalhar. Veremos como descarregar um grande número de imagens do Google utilizando Python. Para treinar uma rede neural, é necessária uma grande quantidade de dados. Quanto mais dados, melhor será o treino. No nosso caso, queremos treinar uma rede neural para reconhecer um determinado objeto. Para isso, criamos um script Python que descarrega os ficheiros da Internet e os coloca numa pasta.
Configurar o Python3
Descarregar as bibliotecas Selenium e OpenCV (opcional)
python3 -m pip install selenium
python3 -m pip install opencv-pythondescarregar ficheiro geckodriver
N.B.: Apenas utilizamos a biblioteca OpenCV para verificar se o OpenCV pode abrir e utilizar as imagens, de modo a não sobrecarregar desnecessariamente a pasta.
Script Python para descarregar imagens
Este script lança uma pesquisa no Google Image e guarda as imagens encontradas na pasta especificada para o banco de imagens.
Nota: Não se esqueça de especificar o caminho para o ficheiro GECKOPATH do geckodriver, o caminho para a pasta de destino e as palavras-chave para a pesquisa no Google.
import sys
import os
import time
#Imports Packages
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import TimeoutException,WebDriverException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import cv2
########################################################################
GECKOPATH = "PATH-TO-GECKODRIVER"
parent_dir = "PATH-TO-FOLDER"
search='coffee mug'
########################################################################
# path
folderName=search.replace(" ","_")
directory = os.path.join(parent_dir, folderName,'img')
# Create the directory
try:
if not os.path.exists(directory):
os.makedirs(directory) #os.mkdir(directory)
except OSError as error:
print("ERROR : {}".format(error))
sys.path.append(GECKOPATH)
#Opens up web driver and goes to Google Images
browser = webdriver.Firefox()#Firefox(firefox_binary=binary)
#load google image
browser.get('https://www.google.ca/imghp?hl=en')
delay = 10 # seconds
try:
btnId="L2AGLb"
myElem = WebDriverWait(browser, delay).until(EC.presence_of_element_located((By.ID , btnId))) #id info-address-place-wrapper
elm=browser.find_element_by_id(btnId)
elm.click()
print("Popup is passed!")
except TimeoutException as e:
print("Loading took too much time!")
# get and fill search bar
box = browser.find_element_by_xpath('//*[@id="sbtc"]/div/div[2]/input')
box.send_keys(search)
box.send_keys(Keys.ENTER)
#Will keep scrolling down the webpage until it cannot scroll no more
last_height = browser.execute_script('return document.body.scrollHeight')
while True:
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(5)
new_height = browser.execute_script('return document.body.scrollHeight')
try:
browser.find_element_by_xpath('//*[@id="islmp"]/div/div/div/div/div[5]/input').click()
time.sleep(5)
except:
print("button not found")
pass
if new_height == last_height:
break
last_height = new_height
imgList=[]
for i in range(1, 1000):
try:
browser.find_element_by_xpath('//*[@id="islrg"]/div[1]/div['+str(i)+']/a[1]/div[1]/img').screenshot(directory+'\{}.png'.format(i))
imgList.add(directory+'\{}.png'.format(i))
except:
pass
browser.quit()
#Test images with OpenCV
for img in imgList:
try:
cv2.imread(img)
except Exception as e:
os.remove(img)
print("remove {}".format(img))
BÓNUS: Gerir um pop-up
No código, adicionei um comando para gerir o pop-up que aparece quando a página Web é aberta. Este comando espera que o botão com o identificador correto seja carregado antes de o premir.
delay = 10 # seconds
try:
btnId="L2AGLb"
myElem = WebDriverWait(browser, delay).until(EC.presence_of_element_located((By.ID , btnId))) #id info-address-place-wrapper
elm=browser.find_element_by_id(btnId)
elm.click()
print("Popup is passed!")
except TimeoutException as e:
print("Loading took too much time!")
Resultados
O script percorre os resultados do Google e tira screenshots de cada imagem para as colocar na nossa base de dados e formar um banco de imagens.
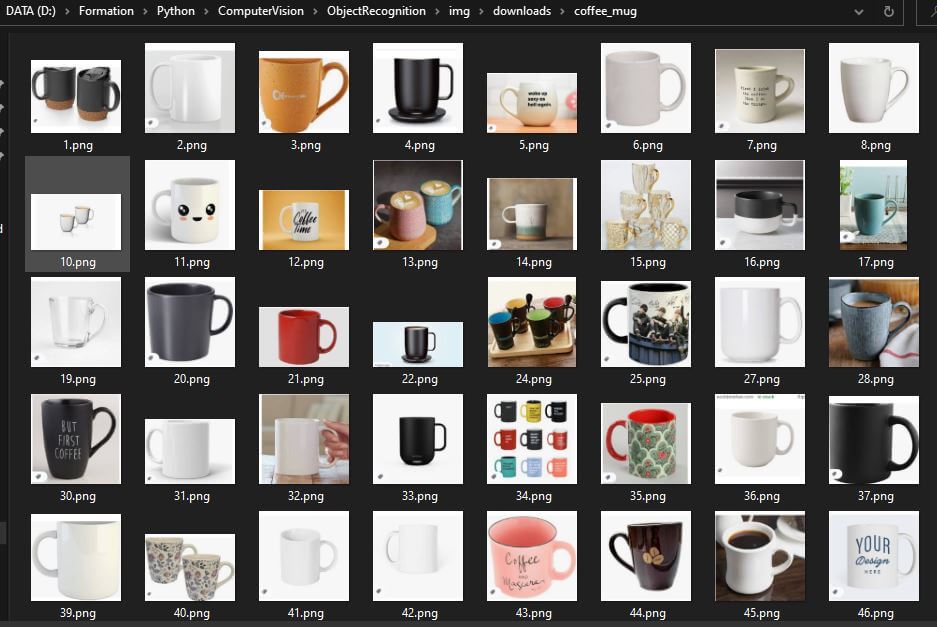
Tem agora um banco de imagens que pode utilizar para reconhecimento visual, por exemplo, ou para processamento de imagens.
Aplicações
- Desenvolver algoritmos de processamento de imagem
- Treino de redes neuronais para deteção e reconhecimento de objectos