Para recolher dados na Internet, pode criar um Web crawler ou Web scraping com Python. Um Web crawler é uma ferramenta que extrai dados de uma ou mais páginas Web.
Configurar o ambiente Python
Assumimos que o Python3 e o pip estão instalados na sua máquina. Também pode usar um ambiente virtual para manter o seu projeto limpo e controlar as versões da biblioteca do seu rastreador web Python.
Primeiro, vamos instalar a biblioteca requests, que permite efetuar pedidos HTTP ao servidor para obter dados.
python -m pip install requests
Para analisar e navegar nos dados da Web, utilizamos a biblioteca Beautiful Soup, que nos permite trabalhar com scripts utilizando etiquetas como HTML ou XML.
python -m pip install beautifulsoup4
Finalmente, estamos a instalar a biblioteca Selenium, que automatiza as tarefas do navegador Web. Pode ser utilizada para apresentar páginas Web dinâmicas e executar acções na interface. Esta biblioteca, por si só, pode ser utilizada para a recolha de dados na Internet, uma vez que pode trabalhar com um sítio Web dinâmico que utilize JavaScript.
python -m pip install selenium
Para que o Selenium funcione com o Mozilla, é necessário descarregar o Geckodriver
Recuperação de uma página Web com resquest
Se pretendermos obter os dados técnicos de uma placa Arduino, podemos carregar a página que pretendemos utilizando requests e bs4
page = requests.get("https://docs.arduino.cc/hardware/uno-rev3/")
content = BeautifulSoup(page.text, 'html.parser')
Ao observar a estrutura da página, pode identificar as etiquetas, classes, identificadores ou textos que lhe interessam. Neste exemplo, recuperamos
- o nome do cartão
- descrição do cartão
N.B.: Pode visualizar a estrutura da página Web no seu programa de navegação clicando com o botão direito do rato na página e seleccionando “Inspecionar”.
import requests
from bs4 import BeautifulSoup
print("Starting Web Crawling ...")
#website to crawl
website="https://docs.arduino.cc/hardware/uno-rev3/"
#google search
#keywords = ["arduino","datasheet"]
#googlesearch = "https://www.google.com/search?client=firefox-b-d&q="
#search = "+".join(keywords)
#website = googlesearch+search
# get page
page = requests.get(website)
#extract html data
content = BeautifulSoup(page.text, 'html.parser')
# extract tags
h1_elms = content.find_all('h1')
print("Board : ",h1_elms)
#get element by class
description = content.find(class_="product-features__description").text
print("Description : ",description)
Starting Web Crawling ... Board : [<h1>UNO R3</h1>] Description : Arduino UNO is a microcontroller board based on the ATmega328P. It has 14 digital input/output pins (of which 6 can be used as PWM outputs), 6 analog inputs, a 16 MHz ceramic resonator, a USB connection, a power jack, an ICSP header and a reset button. It contains everything needed to support the microcontroller; simply connect it to a computer with a USB cable or power it with a AC-to-DC adapter or battery to get started. You can tinker with your UNO without worrying too much about doing something wrong, worst case scenario you can replace the chip for a few dollars and start over again.
Esta operação pode ser completada com uma lista de URLs para vários cartões.
websites = [
"https://docs.arduino.cc/hardware/uno-rev3/",
"https://docs.arduino.cc/hardware/nano/",
"https://docs.arduino.cc/hardware/mega-2560/",
"https://docs.arduino.cc/hardware/leonardo/",
]
Infelizmente, este método não nos permite carregar a lista detalhada das especificações “Tech Specs”, pelo que temos de utilizar o browser.
Configurar um Web Crawler com o Selenium
Carregar uma página é fácil
from selenium import webdriver
GECKOPATH = "PATH_TO_GECKO"
sys.path.append(GECKOPATH)
print("Starting Web Crawling ...")
#website to crawl
website="https://docs.arduino.cc/hardware/uno-rev3/"
#create browser handler
browser = webdriver.Firefox()
browser.get(website)
#browser.quit()
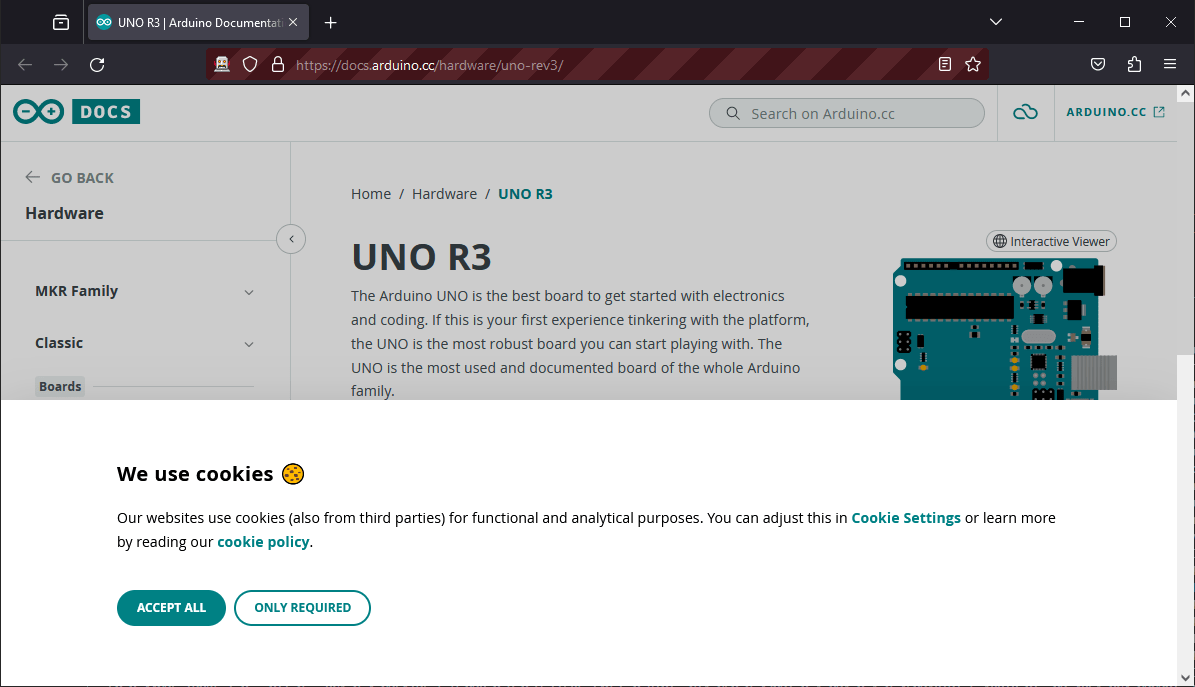
Validação de cookies
Quando a página é apresentada, é provável que se depare com o banner dos cookies, que terá de aceitar ou rejeitar para poder continuar a navegar. Para o fazer, procure e clique no botão “aceitar”
def acceptcookies(): """class="iubenda-cs-accept-btn iubenda-cs-btn-primary""" browser.find_elements(By.CLASS_NAME,"iubenda-cs-accept-btn")[0].click() acceptcookies()
À espera de carregar
Quando a página é apresentada no browser, demora algum tempo a carregar os dados e a apresentar todas as etiquetas. Para esperar que a página seja carregada, pode esperar um período de tempo arbitrário
browser.implicitly_wait(10)
Ou esperar até que uma determinada etiqueta esteja presente, como o botão de aceitação de cookies
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
def waitForElement(locator, timeout ):
elm = WebDriverWait(browser, timeout).until(expected_conditions.presence_of_element_located(locator))
return elm
myElem =waitForElement((By.CLASS_NAME , 'iubenda-cs-accept-btn'),30)
Nota: Se encontrar qualquer outro problema (elemento desconhecido, botão não clicável, etc.) no script quando não há problemas na página Web, não hesite em utilizar a função time.sleep().
Localizar e premir um elemento DOM
Para visualizar as especificações técnicas, o guião deve clicar no separador “Especificações técnicas”. De seguida, é necessário encontrar o elemento a partir do texto. Há duas formas de o fazer: testar o texto do elemento ou utilizar o Xpath
#get element by text
btn_text = 'Tech Specs'
btn_elms = browser.find_elements(By.CLASS_NAME,'tabs')[0].find_elements(By.TAG_NAME,'button')
for btn in btn_elms:
if btn.text == btn_text:
btn.click()
spec_btn = browser.find_element(By.XPATH, "//*[contains(text(),'Tech Specs')]")
spec_btn.click()
Recuperar os dados pretendidos
Quando a página pretendida tiver sido carregada, pode obter os dados
Todos os dados apresentados em forma de tabela
#get all rows and children
print("Tech specs")
print("-------------------------------------")
tr_elms = browser.find_elements(By.TAG_NAME,'tr')
for tr in tr_elms:
th_elms = tr.find_elements(By.XPATH, '*')
if len(th_elms)>1:
print(th_elms[0].text, " : ", th_elms[1].text)
Ou dados específicos
#get parent and siblings
print("Specific data")
print("-------------------------------------")
data_row = browser.find_element(By.XPATH, "//*[contains(text(),'Main Processor')]")
data = data_row.find_element(By.XPATH, "following-sibling::*[1]").text
print(data_row.text, " : ", data)
Resultado da pesquisa de especificações
Starting Web Crawling ... Page is ready! Tech specs ------------------------------------- Name : Arduino UNO R3 SKU : A000066 Built-in LED Pin : 13 Digital I/O Pins : 14 Analog input pins : 6 PWM pins : 6 UART : Yes I2C : Yes SPI : Yes I/O Voltage : 5V Input voltage (nominal) : 7-12V DC Current per I/O Pin : 20 mA Power Supply Connector : Barrel Plug Main Processor : ATmega328P 16 MHz USB-Serial Processor : ATmega16U2 16 MHz ATmega328P : 2KB SRAM, 32KB FLASH, 1KB EEPROM Weight : 25 g Width : 53.4 mm Length : 68.6 mm Specific data ------------------------------------- Main Processor : ATmega328P 16 MHz PS D:\Formation\Python\WebCrawler>
Recuperação de dados de diferentes páginas
Depois de dominar estas ferramentas e ter uma boa ideia dos dados a recuperar e da estrutura das páginas Web, pode extrair dados de várias páginas. Neste último exemplo, estamos a obter dados técnicos de várias placas Arduino. Para isso, criamos um loop que executa o código anterior numa lista de sites
websites = [
"https://docs.arduino.cc/hardware/uno-rev3/",
"https://docs.arduino.cc/hardware/nano/",
"https://docs.arduino.cc/hardware/mega-2560/",
"https://docs.arduino.cc/hardware/leonardo/",
]
import sys
import time
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
GECKOPATH = "D:\\AranaCorp\\Marketing\\Prospects"
sys.path.append(GECKOPATH)
print("Starting Web Crawling ...")
websites = [
"https://docs.arduino.cc/hardware/uno-rev3/",
"https://docs.arduino.cc/hardware/nano/",
"https://docs.arduino.cc/hardware/mega-2560/",
"https://docs.arduino.cc/hardware/leonardo/",
]
#create browser handler
browser = webdriver.Firefox()#Firefox(firefox_binary=binary)
def acceptcookies():
#class="iubenda-cs-accept-btn iubenda-cs-btn-primary
browser.find_elements(By.CLASS_NAME,"iubenda-cs-accept-btn")[0].click()
def waitForElement(locator, timeout ):
elm = WebDriverWait(browser, timeout).until(expected_conditions.presence_of_element_located(locator))
return elm
cookie_accepted=False
for website in websites:
browser.get(website)
time.sleep(2)
if not cookie_accepted: #accept cookie once
myElem =waitForElement((By.CLASS_NAME , 'iubenda-cs-accept-btn'),30)
print("Page is ready!")
acceptcookies()
cookie_accepted = True
else:
myElem =waitForElement((By.CLASS_NAME , 'tabs__item'),30)
#get board name
name = browser.find_element(By.TAG_NAME,'h1').text
#get tab Tech Specs
btn_text = 'Tech Specs'
spec_btn = WebDriverWait(browser, 20).until(expected_conditions.element_to_be_clickable((By.XPATH, "//*[contains(text(),'{}')]".format(btn_text))))
spec_btn.click()
#browser.execute_script("arguments[0].click();", spec_btn) #use script to click
#get all rows and children
print(name+" "+btn_text)
print("-------------------------------------")
tr_elms = browser.find_elements(By.TAG_NAME,'tr')
for tr in tr_elms:
th_elms = tr.find_elements(By.XPATH, '*')
if len(th_elms)>1:
print(th_elms[0].text, " : ", th_elms[1].text)
#get parent and siblings
print("Specific data")
print("-------------------------------------")
try:
data_row = browser.find_element(By.XPATH, "//*[contains(text(),'Main Processor')]")
except:
data_row = browser.find_element(By.XPATH, "//*[contains(text(),'Processor')]")
data = data_row.find_element(By.XPATH, "following-sibling::*[1]").text
print(data_row.text, " : ", data)
browser.quit()
Starting Web Crawling ... Page is ready! UNO R3 Tech Specs ------------------------------------- Main Processor : ATmega328P 16 MHz Nano Tech Specs ------------------------------------- Processor : ATmega328 16 MHz Mega 2560 Rev3 Tech Specs ------------------------------------- Main Processor : ATmega2560 16 MHz Leonardo Tech Specs ------------------------------------- Processor : ATmega32U4 16 MHz
Combinando Selenium e BeautifulSoup
As duas bibliotecas podem ser combinadas para oferecer todas as suas funcionalidades
from bs4 import BeautifulSoup from selenium import webdriver browser = webdriver.Firefox() browser.get(website) html = browser.page_source content = BeautifulSoup(html, 'lxml') browser.quit()
Aplicações
- Automatizar tarefas de recolha de dados na Web
- Crie o seu banco de imagens para treino da rede neural
- Encontrar potenciais clientes
- Realização de estudos de mercado